Síntesis Bivariada y Medidas de Asociación
Unidad 5: Estadística Descriptiva Bivariada
2025-11-24
Hacia una Medida Numérica: La Covarianza
Un gráfico de dispersión es subjetivo. Para cuantificar la relación, necesitamos un número. El primer paso es la covarianza.
La idea es dividir el gráfico en cuatro cuadrantes usando las medias de X e Y.
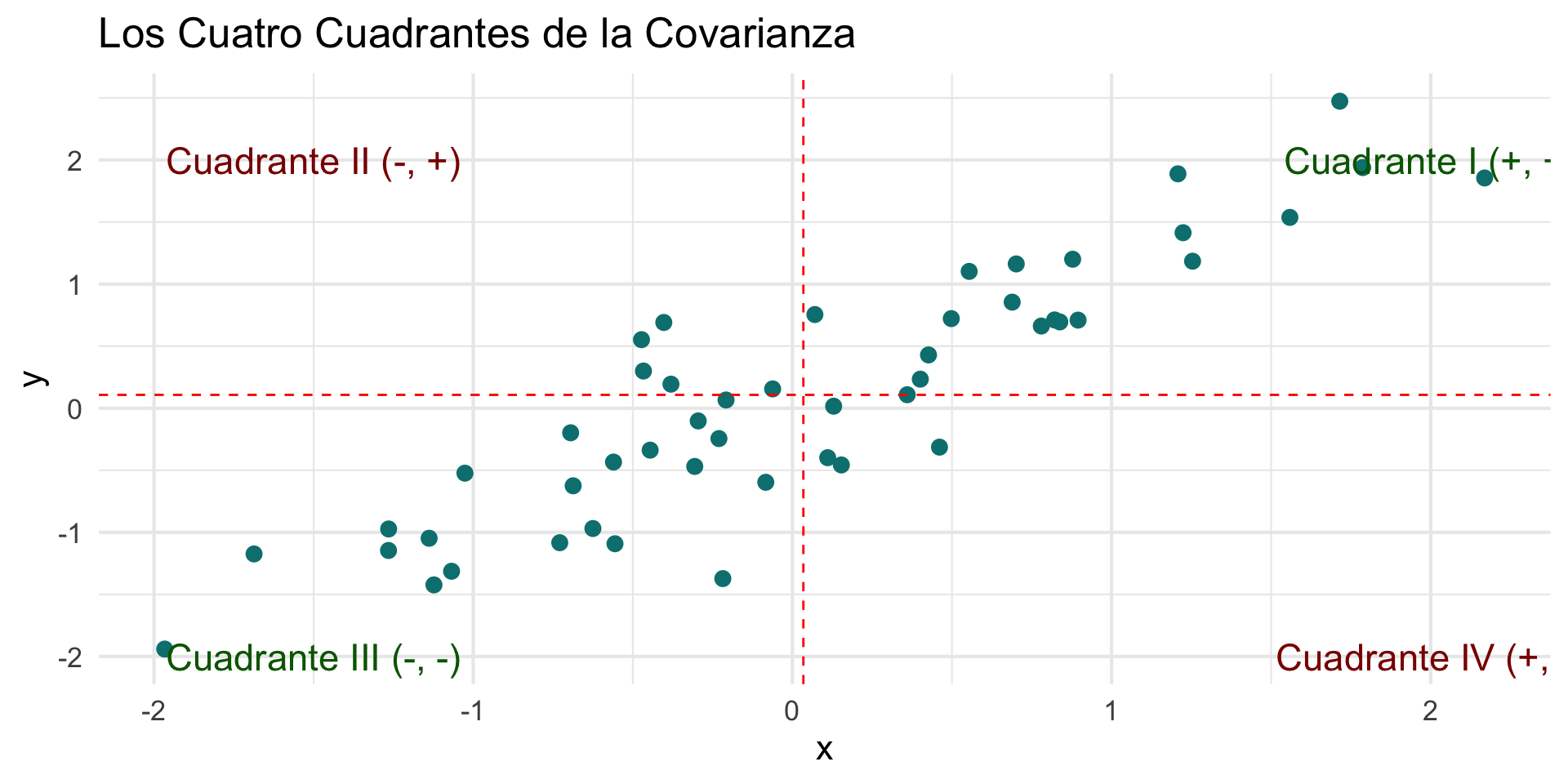
- Asociación Positiva: La mayoría de los puntos caen en los cuadrantes I y III.
- Asociación Negativa: La mayoría de los puntos caen en los cuadrantes II y IV.
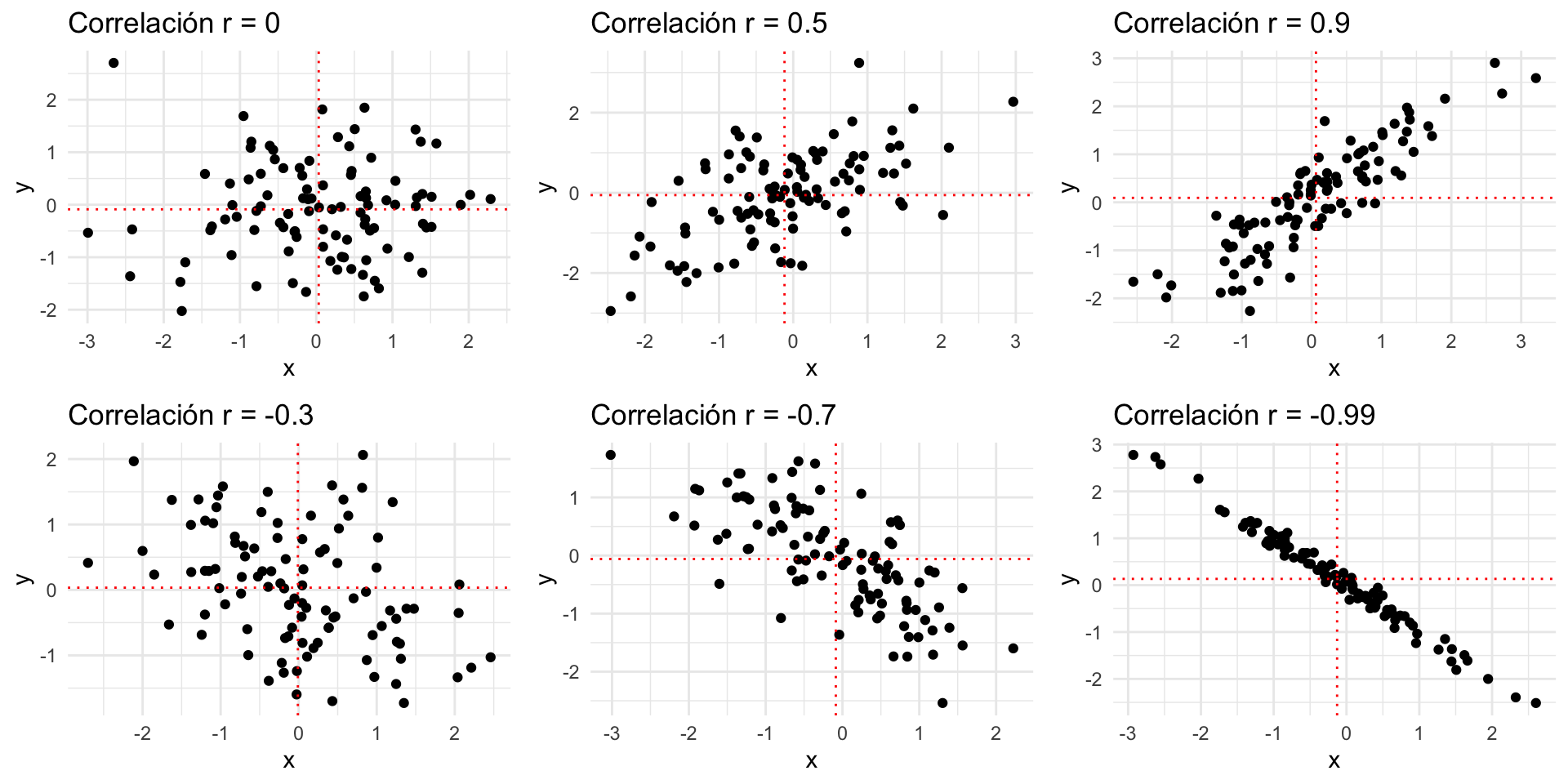
Interpretando la Correlación (r)
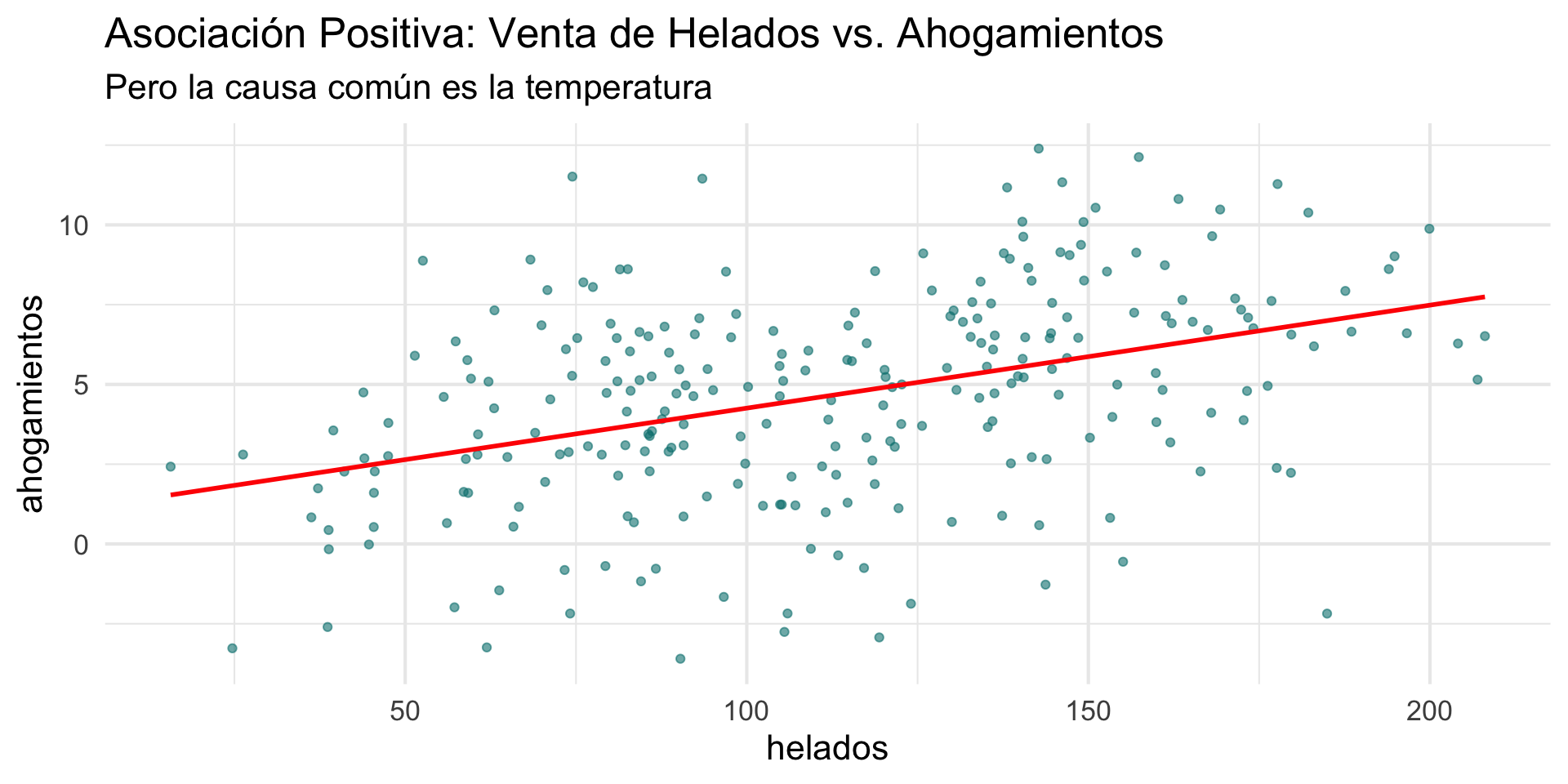
1. Correlación no implica Causalidad
Una correlación fuerte entre dos variables nunca es, por sí sola, evidencia suficiente para concluir que una causa la otra.
La relación podría ser una asociación espuria, causada por una tercera variable latente.
2. La Correlación es Sensible a Outliers
Al igual que la media y la desviación estándar, la correlación es una medida no robusta. Un solo valor atípico puede distorsionar dramáticamente el coeficiente.
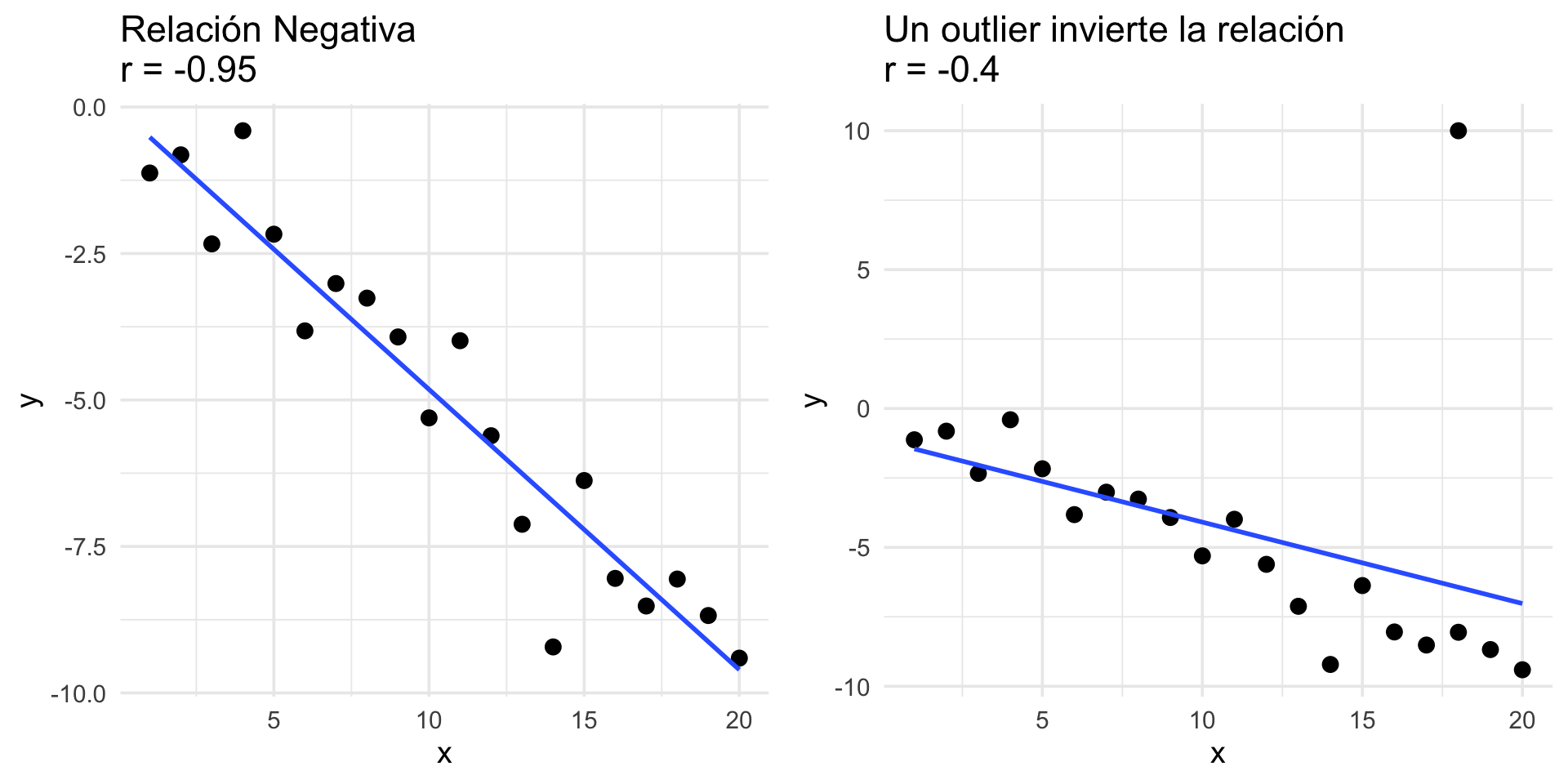
Lección: Siempre inspecciona visualmente tu gráfico de dispersión para detectar outliers antes de interpretar r.
3. r Solo Mide Relaciones LINEALES
El coeficiente de correlación de Pearson está diseñado para medir qué tan bien se ajustan los datos a una línea recta. Si la relación es fuerte pero curvilínea, r puede ser engañosamente bajo.
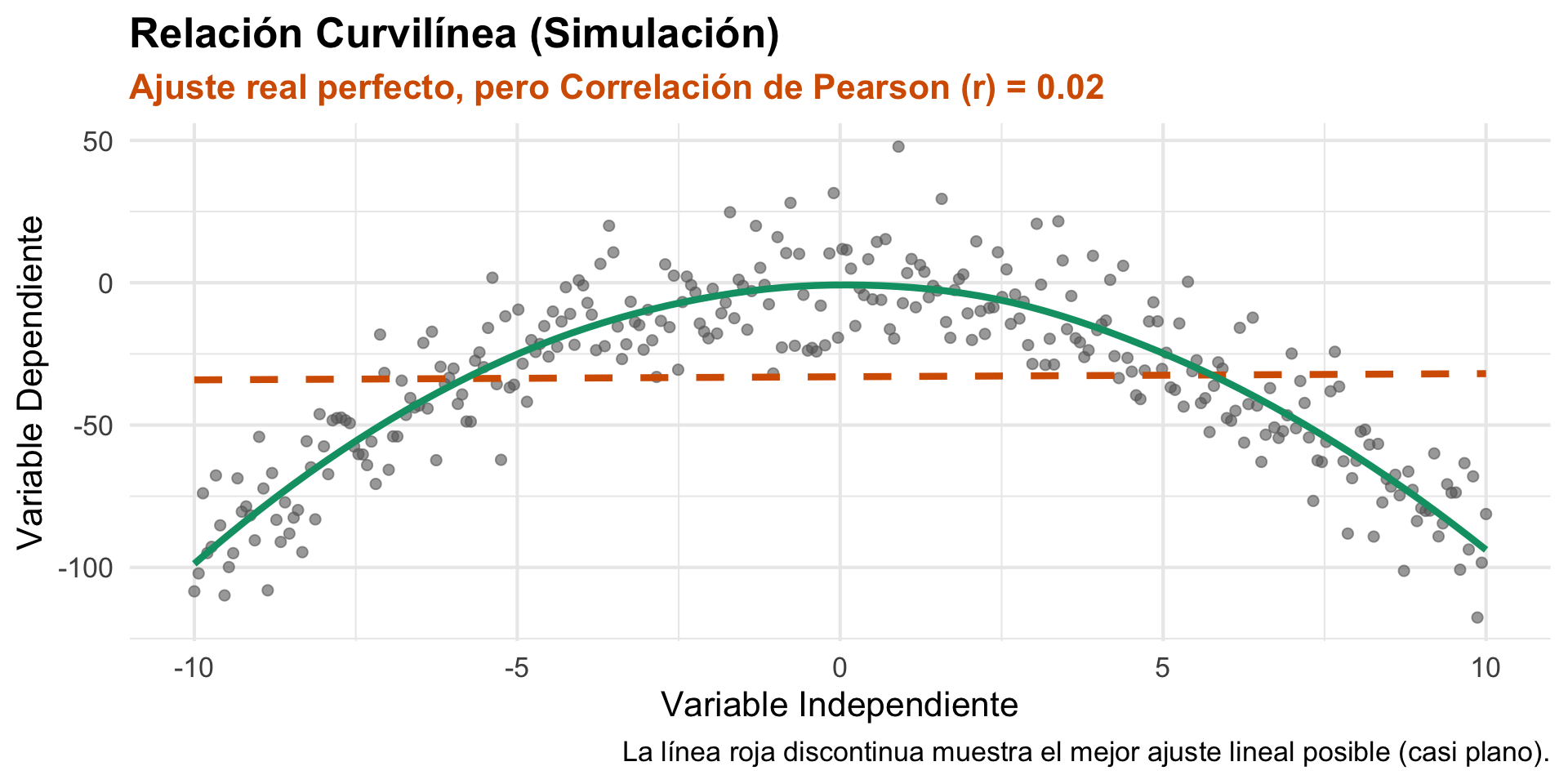
Conclusión: Un r cercano a 0 no significa “ausencia de relación”. Significa “ausencia de relación lineal”. Por eso, el análisis visual es irremplazable.