La Visualización como Argumento Sociológico y la Gramática de Gráficos
Unidad 4: Estadística Descriptiva Univariada
Gabriel Sotomayor
2025-11-03
Objetivos de la Sesión de Hoy
Ver la visualización como argumento sociológico, no solo como ilustración.
Analizar cómo “visualizaciones icónicas” han redefinido debates sobre la desigualdad.
Entender por qué los estadísticos resumen por sí solos pueden ser engañosos.
Aplicar mejores prácticas para crear gráficos claros y honestos.
Conocer la “Gramática de Gráficos” y sus componentes (data, aes, geom).
Usar el faceting en ggplot2 para comparar distribuciones entre grupos.
1. La Visualización como Argumento Sociológico
Más Allá de la Ilustración
En sociología, las visualizaciones más influyentes son, en sí mismas, argumentos teóricos condensados. No son el paso final del análisis: son el análisis.
Pueden:
Contar una historia compleja de forma simple y memorable.
Desafiar narrativas dominantes sobre el progreso y la sociedad.
Redefinir el debate público y académico.
Mike Savage, en The Return of Inequality (Harvard University Press, 2021), llama a estas “visualizaciones icónicas”: proponen una nueva forma de ver el mundo social.
Savage, M. (2021). The Return of Inequality: Social Change and the Weight of the Past. Harvard University Press. https://doi.org/10.2307/j.ctv31xf633
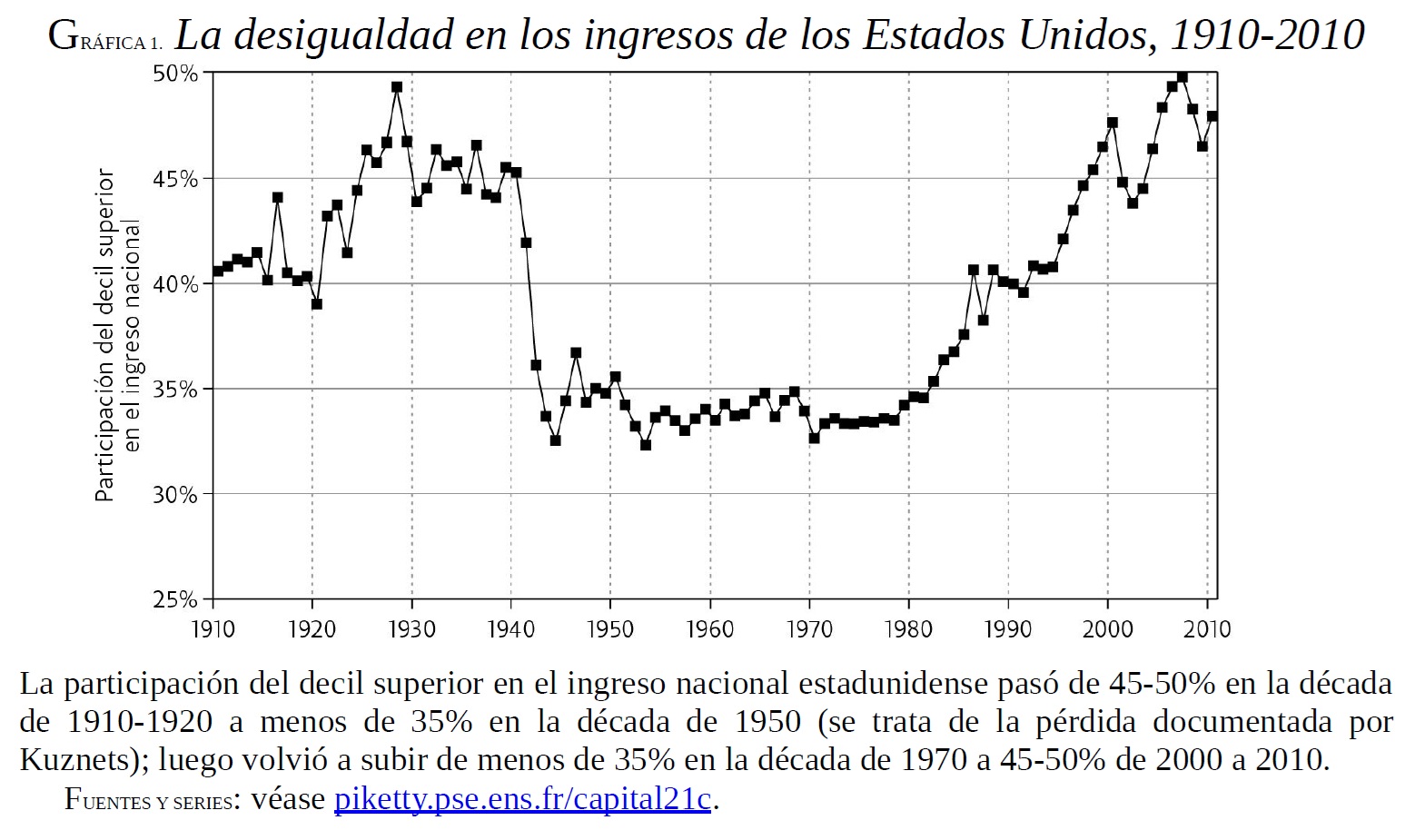
La Curva en U de Piketty (La Desigualdad en el Tiempo)
La Curva en U de Piketty (La Desigualdad en el Tiempo)
El Gráfico: Una simple línea del tiempo (sparkline) que muestra la participación del decil superior en el ingreso nacional de EE.UU. a lo largo del siglo XX.
El Argumento Visual: La forma de “U” es una poderosa narrativa. Desafía la idea modernista de un progreso lineal y constante hacia una mayor igualdad. El gráfico argumenta que, tras un período de relativa equidad a mediados de siglo, estamos “regresando” a los niveles de desigualdad de la “Gilded Age”. Hace visible “el peso de la historia” en el presente.
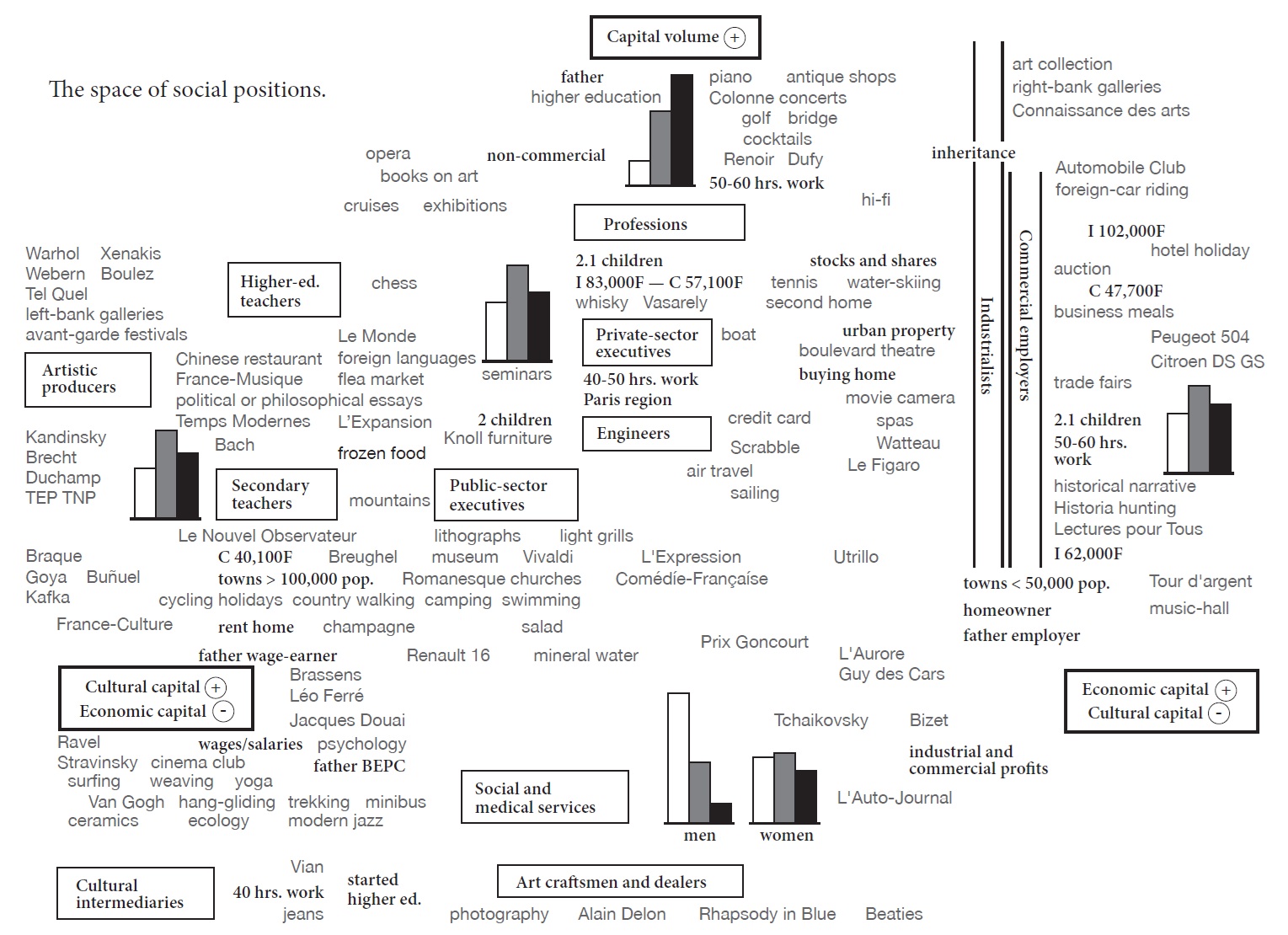
El Espacio Social de Bourdieu (La Desigualdad en el Espacio)
El Espacio Social de Bourdieu (La Desigualdad en el Espacio)
El Gráfico: No es una línea de tiempo, sino un mapa. Posiciona a grupos e individuos en un espacio bidimensional.
Eje Vertical: Volumen total de capital (económico + cultural).
Eje Horizontal: Composición del capital (más cultural a la izquierda, más económico a la derecha).
El Argumento Visual: Bourdieu argumenta que la desigualdad no es una simple jerarquía de ingresos. Es multidimensional y relacional. El gráfico muestra cómo los gustos y estilos de vida (música, arte, comida) no son meras preferencias personales, sino que estructuran el espacio social y reproducen las distinciones de clase.
Ver para argumentar
Savage (2021) señala que Piketty usa el tiempo para argumentar que el pasado está regresando. Bourdieu usa el espacio para mostrar que la desigualdad es multidimensional.
En ambos casos, el gráfico es el núcleo del argumento teórico, no una ilustración de él.
Visualizar bien es hacer sociología.
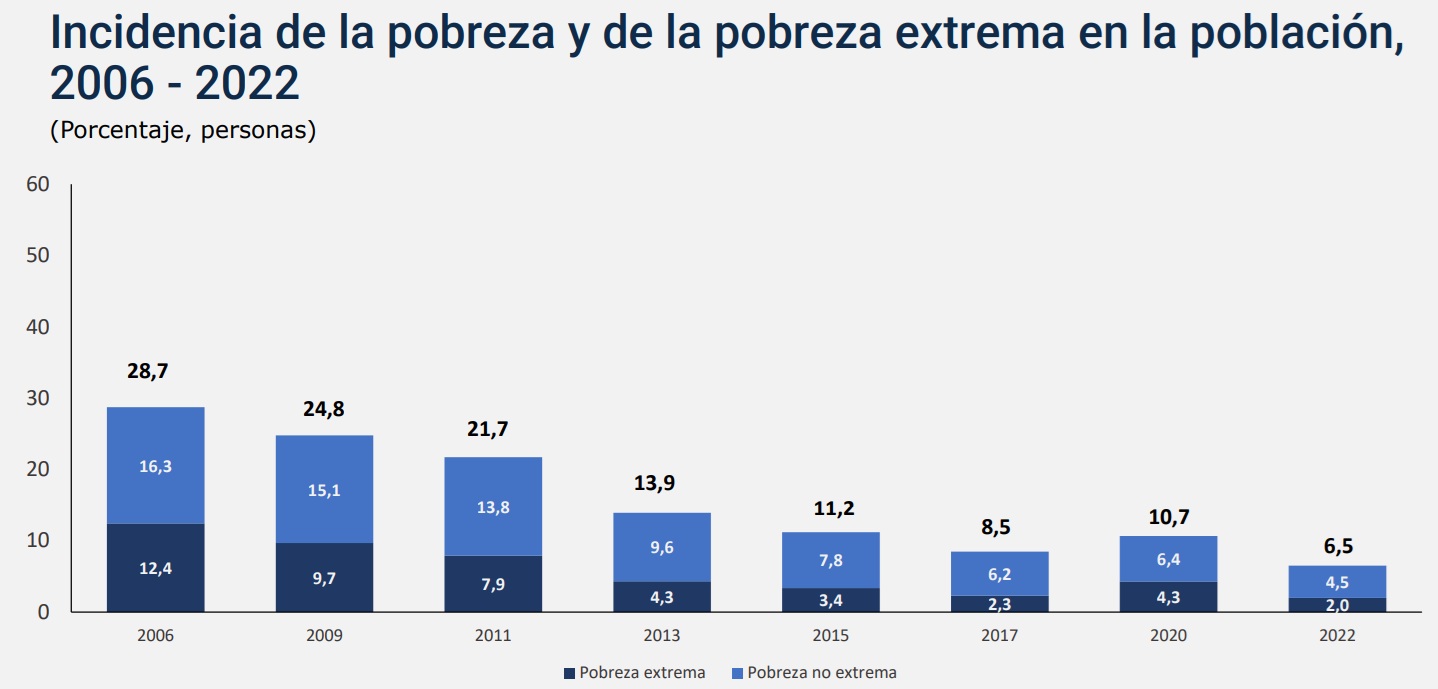
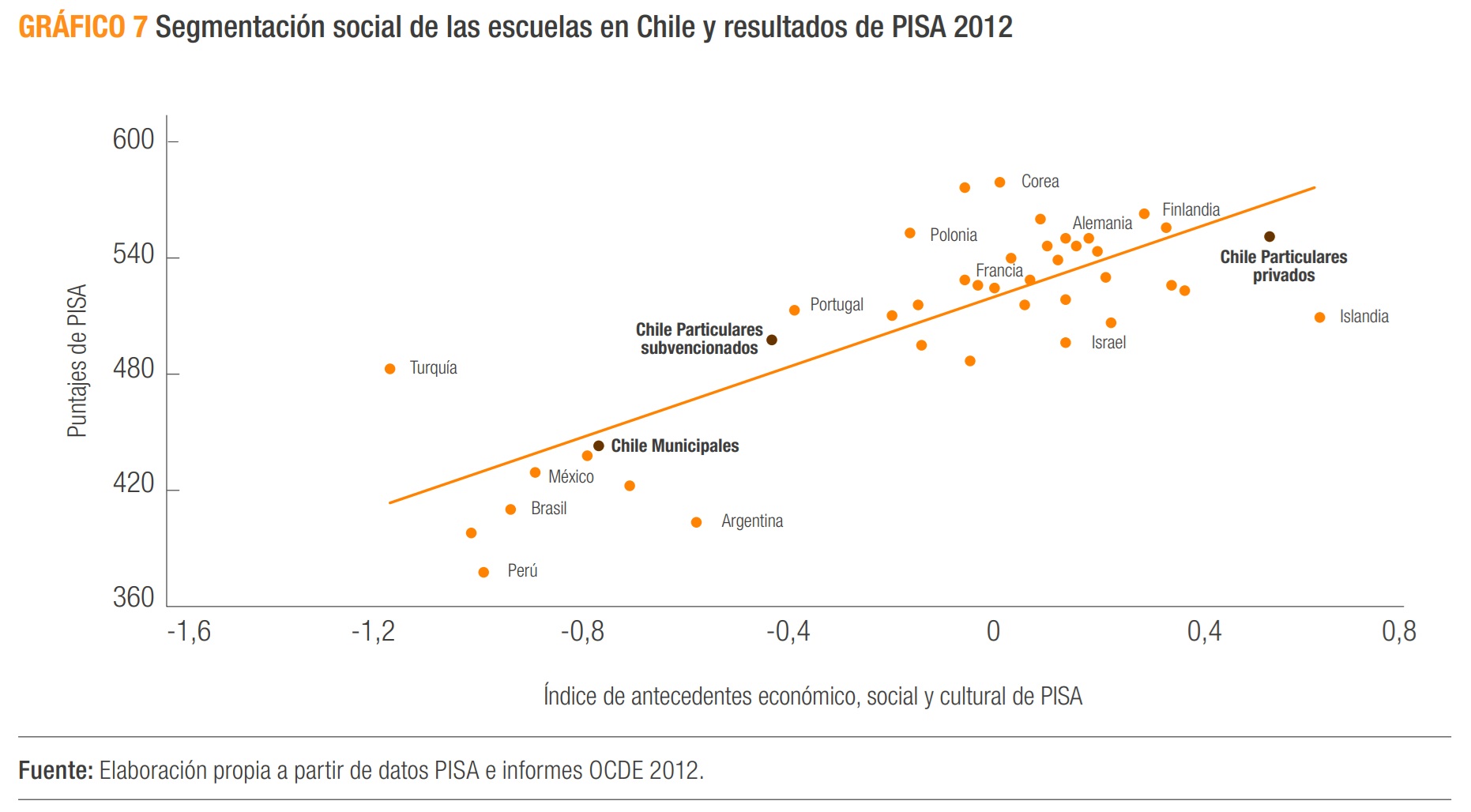
Veamos algunos otros ejemplos
Veamos algunos otros ejemplos
Veamos algunos otros ejemplos
Veamos algunos otros ejemplos
2. La Visualización como Diagnóstico Estadístico
El Engaño de los Estadísticos Descriptivos
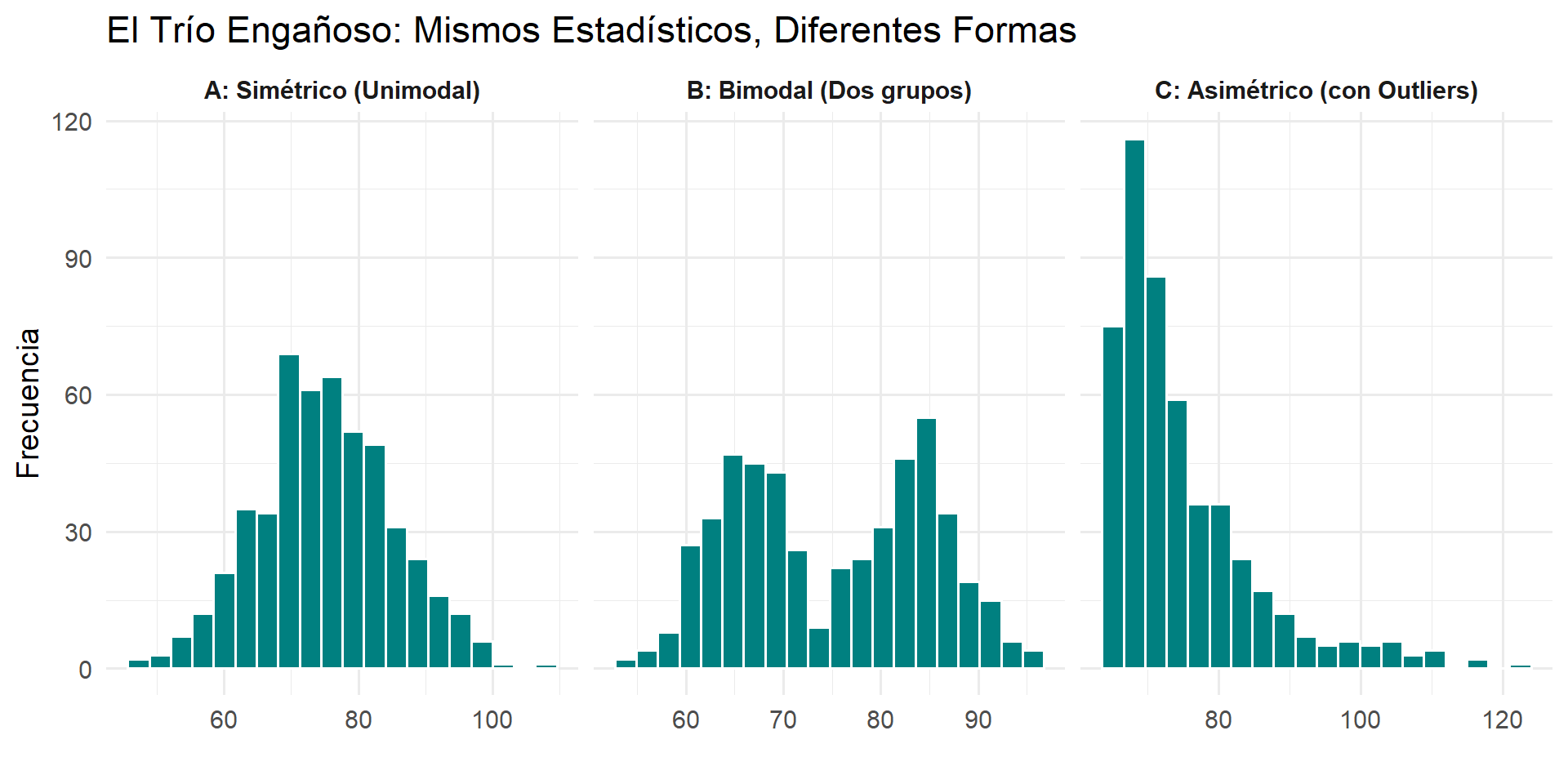
Los gráficos también son herramientas de diagnóstico. Los estadísticos resumen pueden ser idénticos para distribuciones radicalmente diferentes.
Ejemplo: “El Trío Engañoso”
Imaginemos tres grupos de datos con los siguientes estadísticos:
Grupo
Media
Desv. Estándar
A (Notas de Examen)
75.0
10.0
B (Estaturas en cm)
75.0
10.0
C (Ingresos x10,000)
75.0
10.0
Si solo miramos los números, podríamos pensar que las tres distribuciones son similares. Pero…
¡GRAFICA SIEMPRE TUS DATOS!
La visualización revela la verdadera estructura que los números ocultaban.
Lección: La visualización es el único modo de detectar la forma, la modalidad y la presencia de outliers. Es un paso no negociable del análisis de datos.
3. Mejores Prácticas en Visualización
Principios para Gráficos Claros y Honestos
Un buen gráfico cuenta una historia de forma clara, precisa y honesta.
Maximizar la Razón “Tinta-Dato” (Edward Tufte):
Cada elemento visual debe comunicar información. Evita “ruido” como fondos recargados, sombras, efectos 3D o colores que no aportan significado.
Usar Títulos Informativos, no Descriptivos:
Un buen título resume el principal hallazgo o la historia del gráfico.
Mal título: “Gráfico de barras de ingreso por región”.
Buen título: “El ingreso mediano en la RM es un 30% mayor que el promedio nacional”.
Etiquetar Todo Claramente:
Ejes (con sus unidades: $, años, %), leyendas, y siempre citar la fuente.
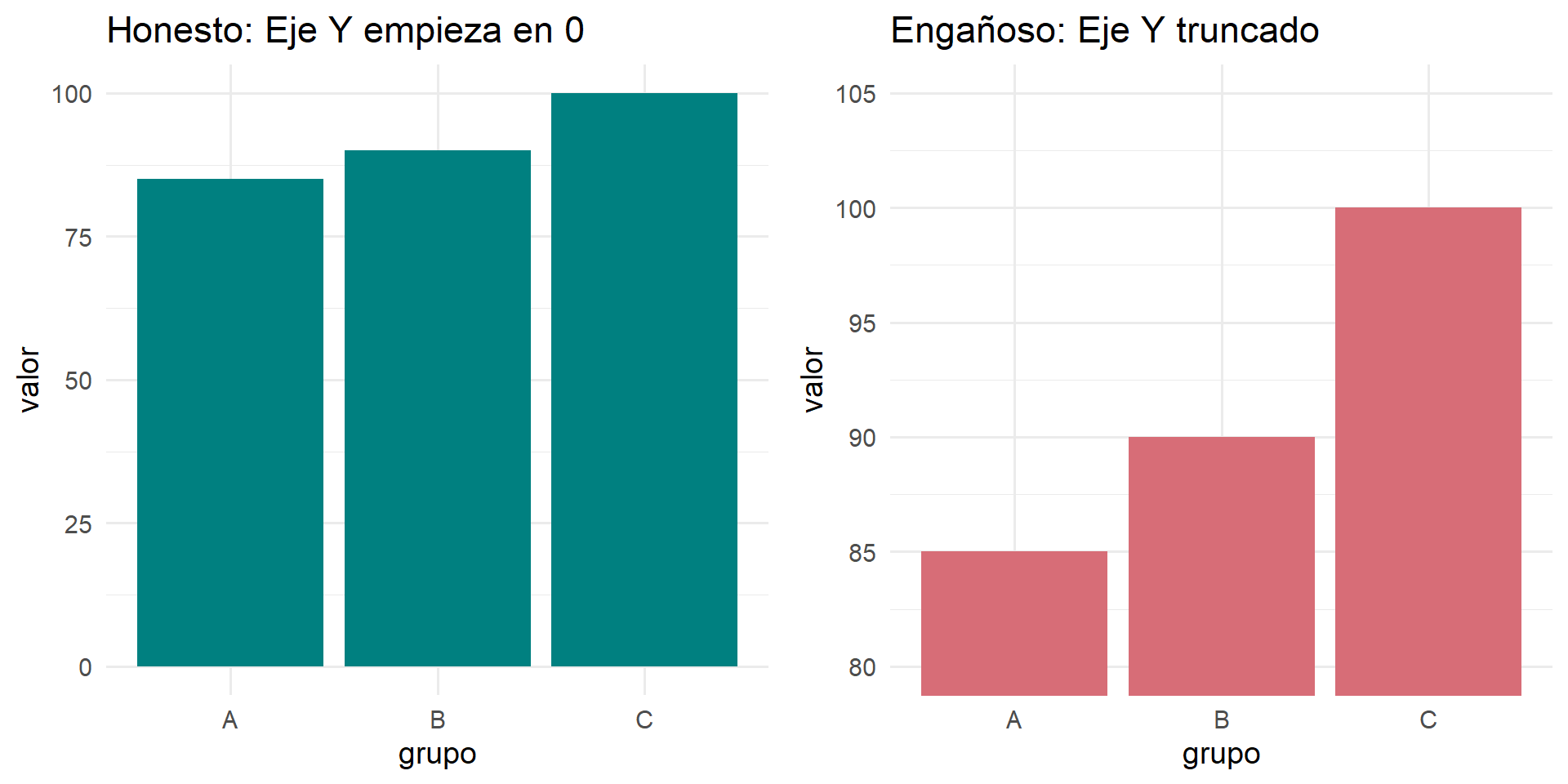
La Regla de Oro del Eje Cero
Los gráficos de barras (y de áreas) SIEMPRE deben empezar en cero.
Nuestros ojos interpretan la longitud o altura de la barra como proporcional a la cantidad que representa. Truncar el eje Y exagera las diferencias y es visualmente deshonesto.
En el gráfico de la derecha, la barra C parece 3 o 4 veces más grande que la A, cuando la diferencia real es solo de un ~18%.
Elige el Gráfico Adecuado
No todos los gráficos sirven para todo. La elección de la geometría depende del tipo de variable(s) que quieres mostrar.
Una variable categórica:Gráfico de Barras. Compara las frecuencias o porcentajes entre categorías.
Una variable cuantitativa:Histograma (para ver la forma), Gráfico de Densidad (versión suavizada) o Boxplot (para el resumen de 5 números).
No uses gráficos de torta (Pie Charts).
Razón: El cerebro humano es muy malo para comparar ángulos y áreas, pero es excelente para comparar longitudes. La altura de las barras en un gráfico de barras es mucho más fácil de interpretar con precisión.
4. La Gramática de Gráficos con ggplot2
Un Sistema para Construir Gráficos en Capas
ggplot2 es un paquete de R que implementa la “Gramática de Gráficos”, una idea poderosa: en lugar de tener comandos rígidos para cada tipo de gráfico, tenemos un sistema de “bloques de construcción” que podemos combinar para crear cualquier visualización que imaginemos.
Un gráfico en ggplot2 es una superposición de capas.
Los 3 Componentes Esenciales
Toda visualización en ggplot2 se construye a partir de tres componentes fundamentales:
Datos (data): El data.frame que contiene la información que queremos visualizar.
Mapeos Estéticos (aes): La conexión entre las variables de nuestros datos y las propiedades visuales (estéticas) del gráfico.
aes(x = edad, y = ytotcorh, color = sexo)
Esto le dice a ggplot2: “Usa la columna edad para el eje X, ytotcorh para el eje Y, y asigna un color diferente para cada valor de la variable sexo”.
Geometrías (geom): El objeto geométrico que usamos para representar los datos. Es la “forma” que toma nuestra visualización.
ggplot(...): Inicia el gráfico. Define la fuente de datos y los mapeos globales. Crea un lienzo en blanco con los ejes definidos, listo para recibir una geometría.
+: El operador para añadir una nueva capa.
geom_...(): Añade la capa de geometría que dibuja los datos en el lienzo.
Construyendo por Capas: Ejemplo
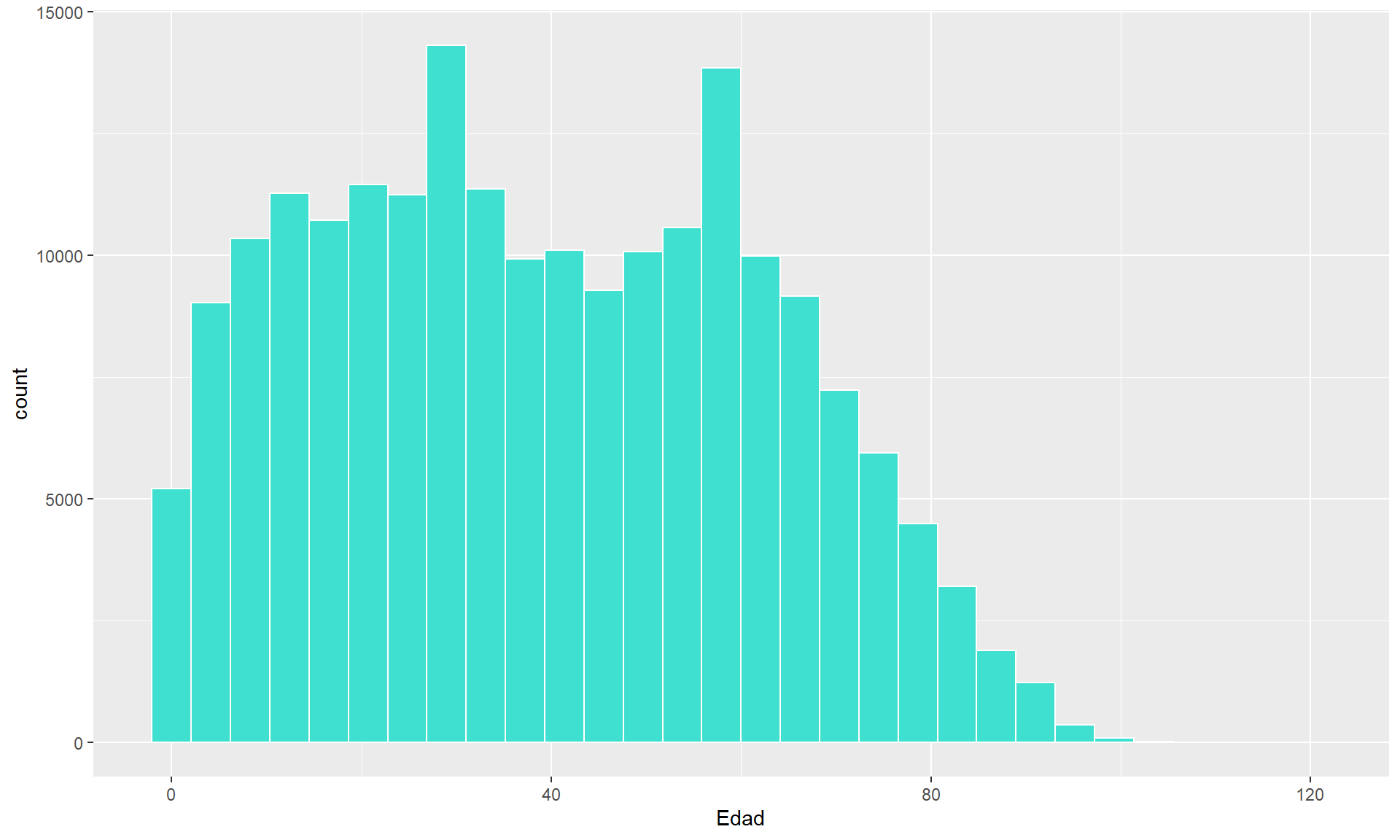
Paso 1: ggplot() crea el lienzo. Le decimos qué datos usar y qué variables mapear a los ejes. El resultado es un plano cartesiano vacío.
# Capa 1: Datos y Estéticasggplot(data = casen, mapping =aes(x = edad))
Construyendo por Capas: Ejemplo
Paso 2: + geom_histogram() añade la capa que dibuja. Le decimos que represente los datos mapeados como un histograma.
Es la distinción que más confunde al principio, pero que define cómo funciona ggplot2.
Mapear (DENTRO de aes()):
El atributo visual depende de una variable. El gráfico usa el color (o el tamaño, etc.) para representar información.
aes(color = sexo)
El color de cada punto depende del valor de sexo.
Fijar (FUERA de aes()):
Se asigna un valor constante. Es una decisión estética, no informativa.
geom_point(color ="blue")
Todos los puntos son azules, sin excepción.
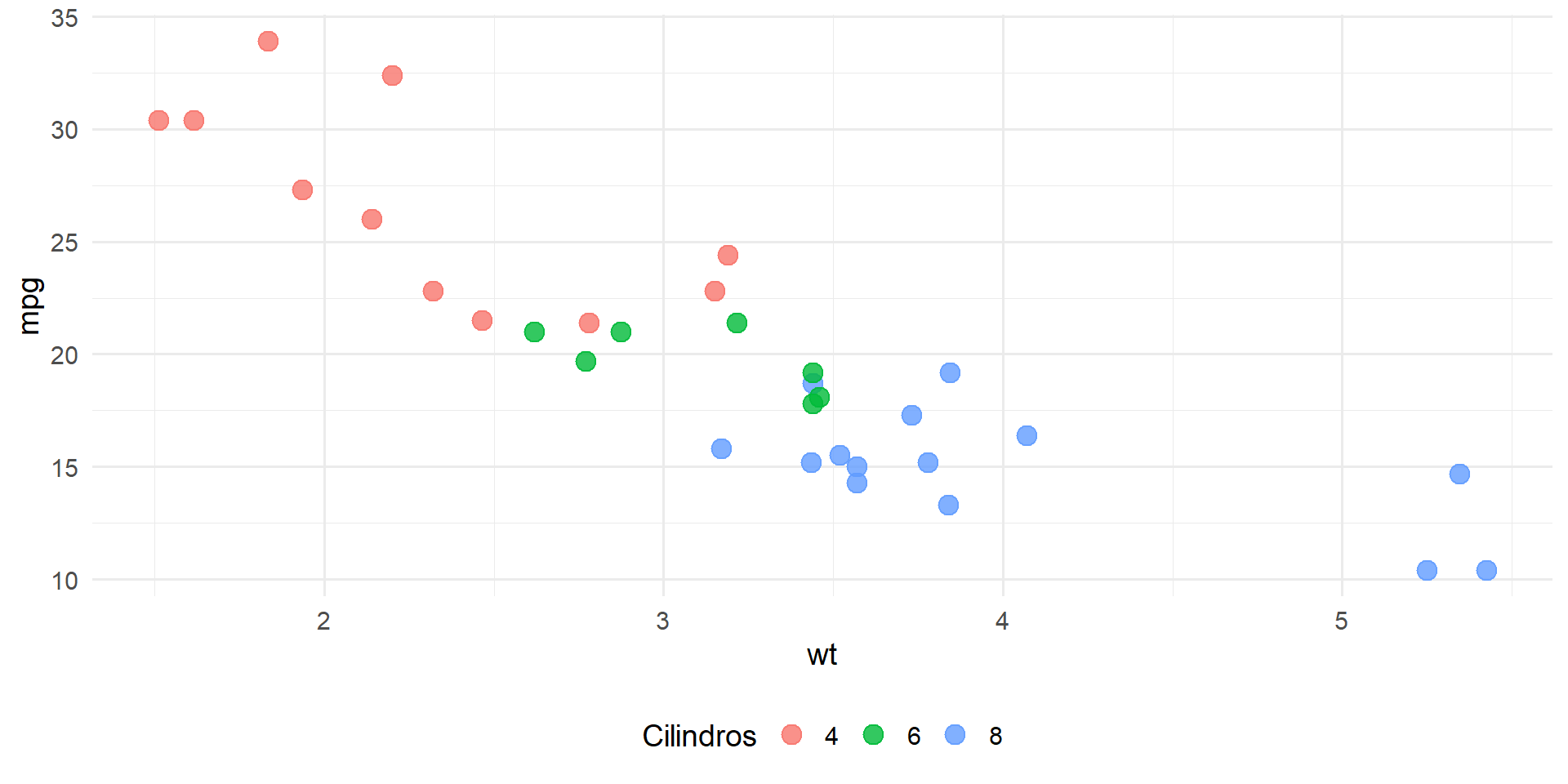
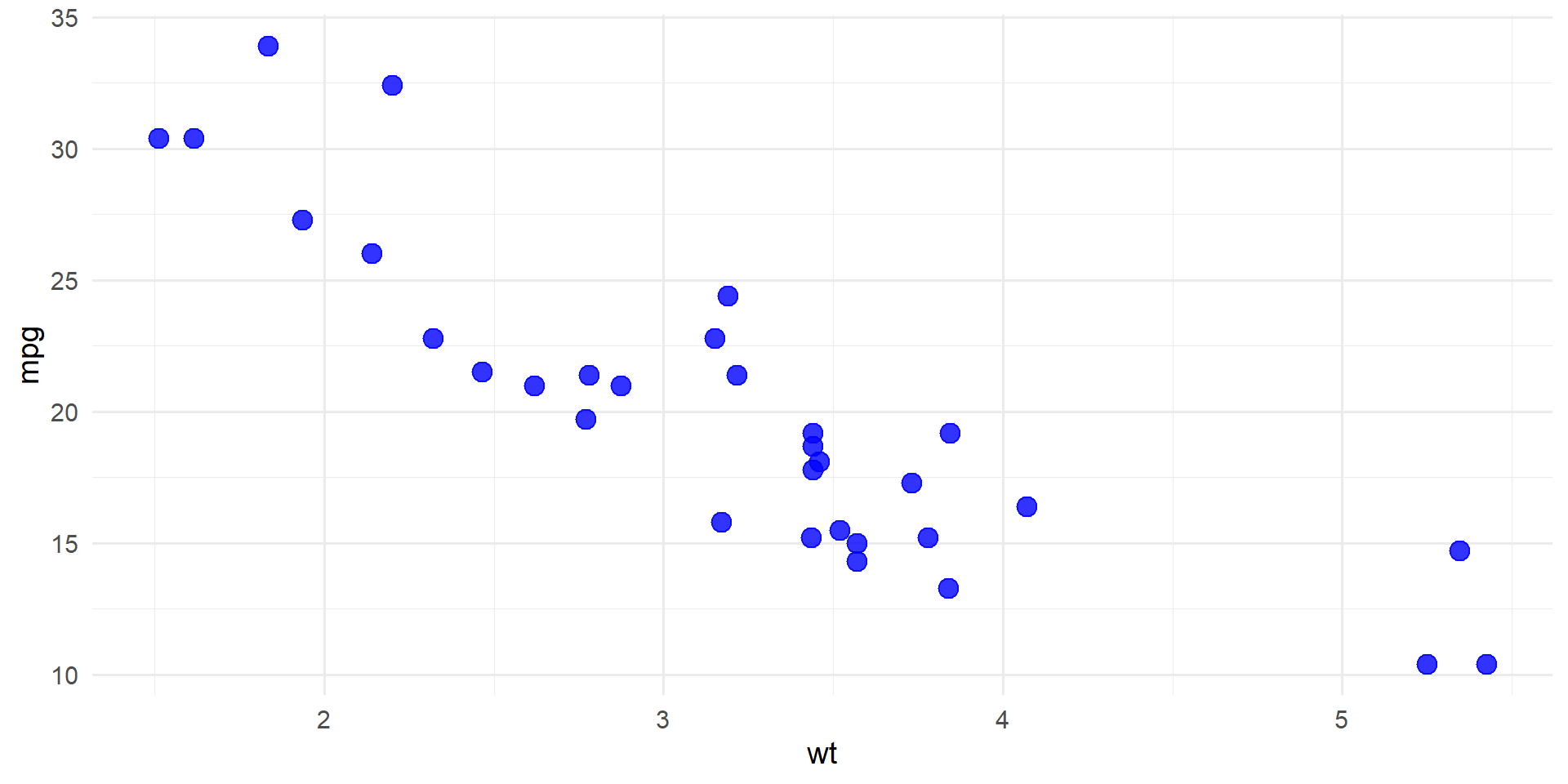
Mapear vs. Fijar: Ejemplo Visual
Dispersión del peso (wt) vs. rendimiento (mpg) en mtcars.
Mapeando color a cyl: el color representa información.
ggplot(mtcars, aes(x = wt, y = mpg, color =as.factor(cyl))) +geom_point(size =3, alpha =0.8) +labs(color ="Cilindros") +theme_minimal(base_size =11) +theme(legend.position="bottom")
Fijando color a “blue”: todos los puntos iguales.
ggplot(mtcars, aes(x = wt, y = mpg)) +geom_point(size =3, alpha =0.8, color ="blue") +theme_minimal(base_size =11)
Ampliando la Gramática: Faceting (Small Multiples)
El Problema: ¿Qué pasa si queremos comparar la distribución del ingreso a través de las 16 regiones de Chile? Mapear 16 colores a una estética se vuelve un caos visual.
La Solución: El Faceting (facet_wrap() o facet_grid())
Consiste en crear una grilla de gráficos más pequeños, donde cada panel muestra un subconjunto de los datos. Es una de las herramientas más poderosas de ggplot2 para el análisis exploratorio.
ggplot(datos, aes(x = ingreso)) +geom_histogram() +facet_wrap(~ region) # Crea un histograma separado para cada región
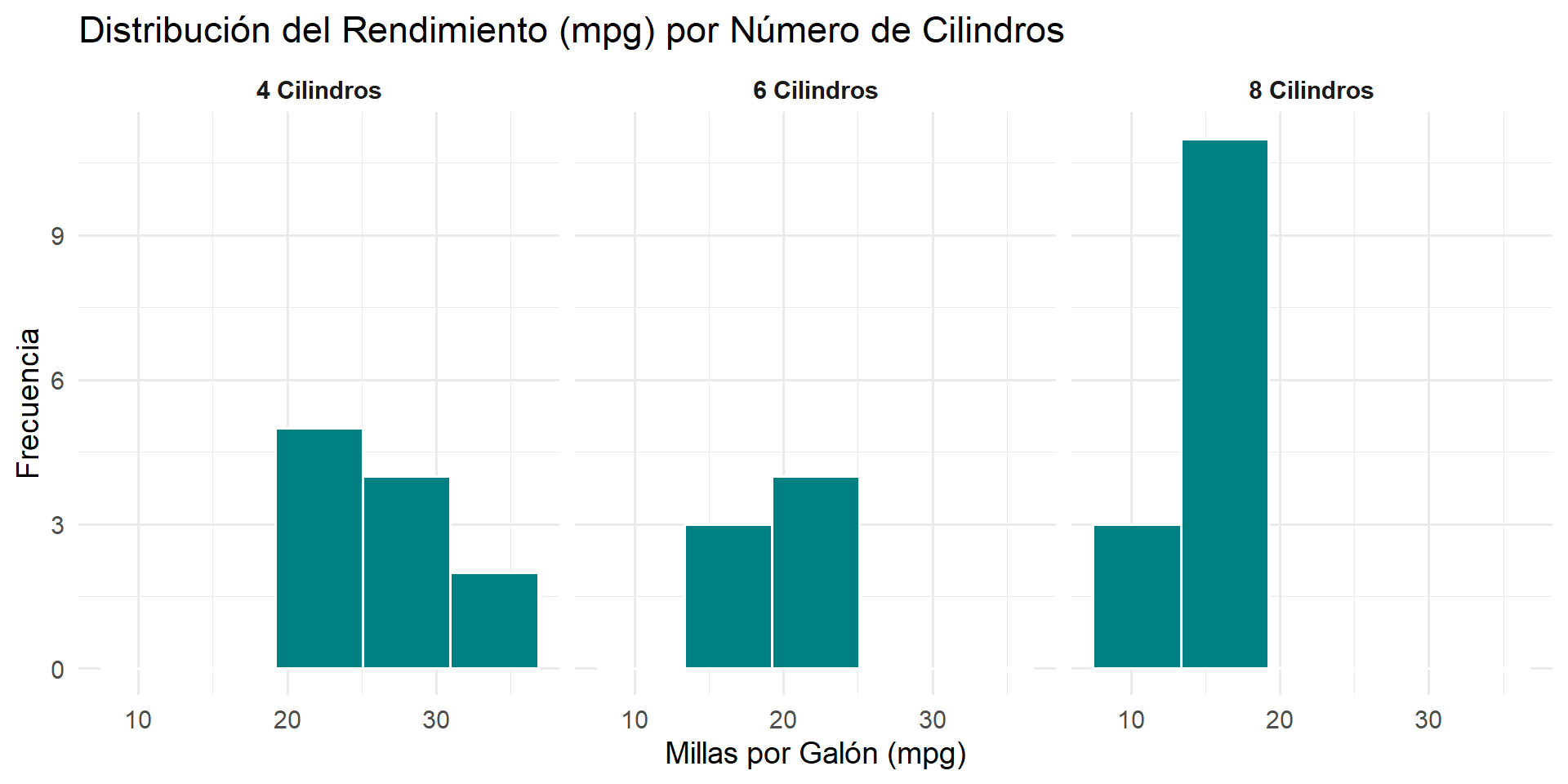
Faceting en Acción
Ahora, usemos facet_wrap() para comparar la distribución del rendimiento (mpg) para cada tipo de cilindro (cyl). En lugar de usar colores en un solo gráfico, creamos un panel para cada categoría.
Cierre y Próximos Pasos
Resumen de la sesión de hoy:
La visualización es una forma de argumento sociológico y una herramienta de diagnóstico estadístico indispensable.
Crear gráficos efectivos y honestos requiere seguir buenas prácticas.
ggplot2 usa una “Gramática de Gráficos” que nos permite construir visualizaciones complejas añadiendo capas (data, aes, geom).
El faceting es una técnica clave para comparar distribuciones a través de múltiples categorías.
En el práctico de hoy:
Aplicarán estos principios para diagnosticar datos, construir sus primeros gráficos con ggplot2 desde cero y usar facet_wrap para análisis comparativos con la CASEN 2022.
Adelanto de la Unidad 5:
En la próxima unidad, dejaremos el análisis univariado y nos adentraremos de lleno en el análisis bivariado: cómo describir la relación entre dos variables.