Los Datos Tienen Contexto
“La estadística trata sobre datos. Éstos son números, pero no sólo son eso. Los datos son números en un contexto.” — David S. Moore (2005)
El número 3.75 por sí solo no significa nada. - Si es el peso de un bebé en kilos, es una excelente noticia. - Si es el peso de un bebé en gramos, es una tragedia.
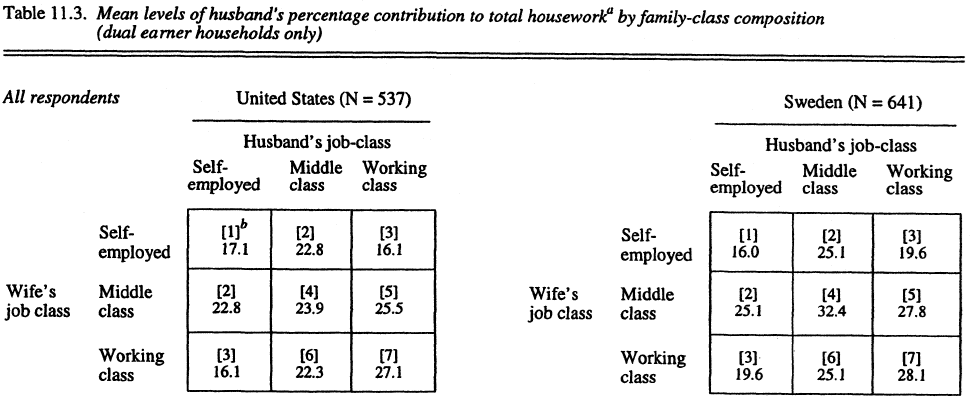
En sociología, el contexto es todo. La estadística nos ayuda a interpretar números dentro de un marco social significativo. Un 10% de desempleo no es solo un número; representa vidas, políticas y estructuras sociales.
La Sociología como Ciencia de la Población (2015)
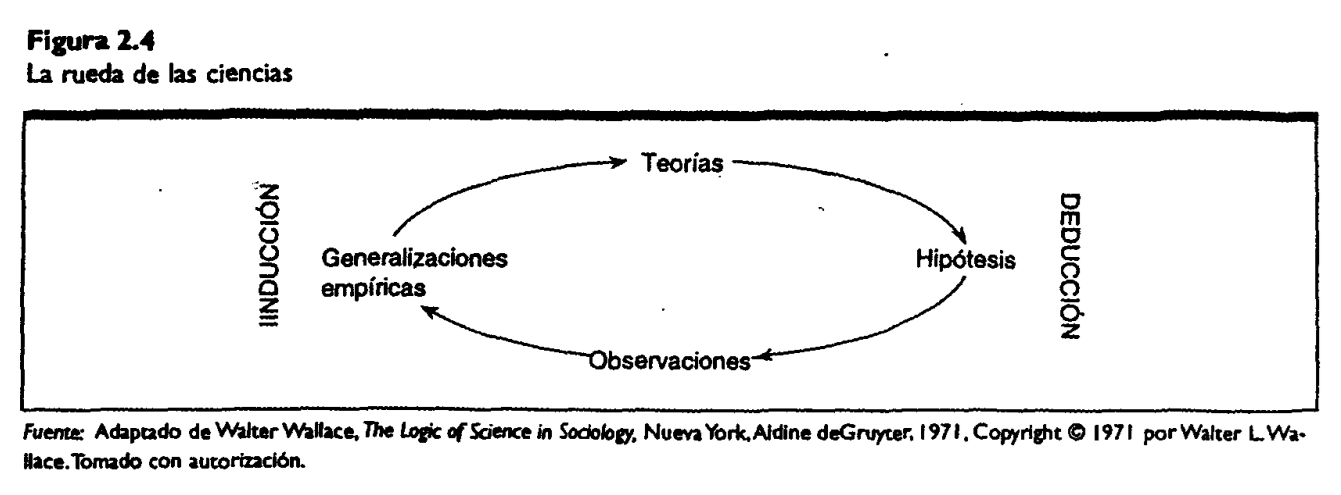
En este libro Goldthorpe plantea que la tarea fundamental de la sociología es explicar las regularidades de la población, la variabilidad que se produce a nivel individual.
Dada dicha variabilidad y por la autonomía que retiene la acción individual aún ante la existencia de condicionamientos socioculturales, la acción individual debe tener una primacía explicativa (cf. Weber y Durkheim).
Dado el énfasis en la acción individual, la estadística juega un rol fundamental para medir y analizar regularidades poblacionales (en conjunción con objetos sociológicos).
El objetivo explicativo de la sociología es dar cuenta de los mecanismos (individuales) que permiten generara las regularidades observadas en la población.