Análisis Categórico Bivariado: Tablas de Contingencia y Control
0. Objetivos del Práctico
El objetivo de este práctico es dominar las herramientas para analizar la relación entre dos variables categóricas. Al finalizar, serás capaz de:
- Utilizar
table()yproportions()de R base para una exploración rápida. - Construir e interpretar tablas de contingencia ponderadas usando un flujo de
dplyryjanitor. - Aplicar el procedimiento de análisis: calcular porcentajes en la dirección de la variable explicativa y comparar en la opuesta.
- Visualizar relaciones categóricas bivariadas con
ggplot2, comparando flujos de trabajo. - Implementar el análisis de control estratificando por una tercera variable.
1. Contexto y Preparación de Datos
1.1 Contexto del Práctico
Hoy nos sumergiremos en el Caso 2 (Categórica ➞ Categórica) del análisis bivariado. Nuestra herramienta principal será la tabla de contingencia, que nos permitirá analizar cómo la distribución de una variable categórica (Y) cambia a través de las categorías de otra (X). Utilizaremos la Encuesta Nacional de Uso del Tiempo (ENUT) 2023 para explorar las desigualdades en la distribución del trabajo y el bienestar.
1.2 Preparación del Entorno y Datos
Paso 1: Organiza tu entorno
Como siempre, asegúrate de estar trabajando dentro de tu Proyecto de RStudio y de tener una carpeta datos.
Paso 2: Descarga la Base de Datos
Descarga la base de datos de la ENUT 2023 desde el siguiente enlace y guarda el archivo .zip en tu carpeta datos:
- Enlace de descarga: Base de datos ENUT 2023 (formato R)
Paso 3: Carga de Paquetes y Datos
# Cargar paquetes
library(tidyverse)
library(haven)
library(rio) # Para importar datos fácilmente
library(janitor) # Para crear tablas de contingencia
library(knitr) # Para dar formato a las tablas
library(kableExtra)# Para estilos adicionales a las tablas
# Carga Manual (Método recomendado)
enut <- rio::import("datos/250403-ii-enut-bdd-r-v2.zip", which = "250403-ii-enut-bdd-r-v2.RDS")
El siguiente bloque carga los datos automáticamente para la reproducibilidad del documento.
# Carga automática de datos
enut <- rio::import("https://www.ine.gob.cl/docs/default-source/uso-del-tiempo-tiempo-libre/bbdd/ii-enut/250403-ii-enut-bdd-r-v2.zip?sfvrsn=87682f16_7", which = "250403-ii-enut-bdd-r-v2.RDS")
1.3 Limpieza y Preparación de Variables
Crearemos un único dataframe llamado enut_practico que contenga todas las variables que usaremos, ya limpias y transformadas a formato factorial.
enut_practico <- enut %>%
filter(tiempo == 1) %>% # Nos quedamos solo con quienes contestaron el diario de tiempo
mutate(
sexo_factor = as_factor(sexo),
p_tdnr_dt_factor = as_factor(p_tdnr_dt),
p_tcnr_dt_factor = as_factor(p_tcnr_dt),
cae_factor = as_factor(cae),
bs2_factor = as_factor(bs2),
nivel_educ_factor = fct_recode(as_factor(nivel_educ),
"Básica (in)completa" = "Sin educación primaria o primaria incompleta",
"Básica (in)completa" = "Primaria completa",
"Media" = "Secundaria completa",
"Técnica" = "Técnica o postsecundaria no terciaria",
"Universitaria" = "Universitaria completa"),
grupo_edad = case_when(
edad <= 29 ~ "Jóvenes (12-29)",
edad <= 59 ~ "Adultos (30-59)",
edad >= 60 ~ "Adultos Mayores (60+)"
)
) %>%
filter(
cae_factor %in% c("Persona ocupada", "Persona desocupada", "Personas fuera de la fuerza de trabajo")
)
2. Exploración Rápida con R Base: table() y proportions()
Antes de crear tablas de publicación, es útil hacer una exploración rápida de la muestra sin ponderar.
# 1. Crear una tabla de contingencia con frecuencias absolutas
tabla_simple <- table(enut_practico$sexo_factor, enut_practico$cae_factor)
tabla_simple
##
## Menores de 15 años Persona ocupada Persona desocupada
## Hombre 0 7551 480
## Mujer 0 8068 554
## Valor Perdido 0 0 0
##
## Personas fuera de la fuerza de trabajo
## Hombre 3258
## Mujer 7461
## Valor Perdido 0
# 2. Calcular porcentajes de columna (margin = 2)
proportions(tabla_simple, margin = 2) %>% round(2)
##
## Menores de 15 años Persona ocupada Persona desocupada
## Hombre 0.48 0.46
## Mujer 0.52 0.54
## Valor Perdido 0.00 0.00
##
## Personas fuera de la fuerza de trabajo
## Hombre 0.30
## Mujer 0.70
## Valor Perdido 0.00
# 3. Calcular porcentajes de fila (margin = 1)
proportions(tabla_simple, margin = 1) %>% round(2)
##
## Menores de 15 años Persona ocupada Persona desocupada
## Hombre 0.00 0.67 0.04
## Mujer 0.00 0.50 0.03
## Valor Perdido
##
## Personas fuera de la fuerza de trabajo
## Hombre 0.29
## Mujer 0.46
## Valor Perdido
Interpretación: Estas funciones son excelentes para una inspección inicial. Por ejemplo, en los porcentajes de columna, vemos que el 52% de las personas ocupadas en la muestra son mujeres. Sin embargo, para hacer afirmaciones sobre la población, necesitamos usar los ponderadores.
3. Creando Tablas de Publicación Ponderadas
Para crear tablas ponderadas, usaremos un flujo que combina dplyr (para el cálculo) y janitor (para el formato).
# Flujo correcto para crear una tabla ponderada de porcentajes de columna
enut_practico %>%
# Paso 1: Contar las combinaciones ponderadas con dplyr
count(cae_factor, sexo_factor, wt = fe_cut, name = "n_pond") %>%
# Paso 2: Reestructurar a formato ancho
pivot_wider(names_from = sexo_factor, values_from = n_pond) %>%
# Paso 3: Usar janitor para adornar la tabla con totales y porcentajes
adorn_totals("row") %>%
adorn_percentages("col") %>%
adorn_pct_formatting(digits = 1) %>%
adorn_ns("front") %>%
# Paso 4: Presentar con kable
kable(caption = "Condición de Actividad por Sexo (%)") %>%
kable_styling(bootstrap_options = "striped", full_width = FALSE)
| cae_factor | Hombre | Mujer |
|---|---|---|
| Persona ocupada | 4,891,103.4 (69.3%) | 3,931,116.0 (52.6%) |
| Persona desocupada | 338,414.7 (4.8%) | 294,875.5 (3.9%) |
| Personas fuera de la fuerza de trabajo | 1,825,378.7 (25.9%) | 3,254,677.4 (43.5%) |
| Total | 7,054,896.8 (100.0%) | 7,480,668.9 (100.0%) |
3.1 Actividad 1
Pregunta: Usando el flujo completo (count -> pivot_wider -> adorn_... -> kable), crea e interpreta una tabla ponderada que muestre la relación entre el nivel educacional (nivel_educ_factor) (X, en las columnas) y la condición de actividad (cae_factor) (Y, en las filas). ¿Qué nivel educativo presenta el mayor porcentaje de ‘Personas Ocupadas’?
# Escribe aquí tu código para la Actividad 1
4. Visualizando Relaciones Categóricas
4.1 Flujo 1: Graficar Directamente (position = "fill")
Este método es el más rápido: ggplot2 calcula las proporciones internamente.
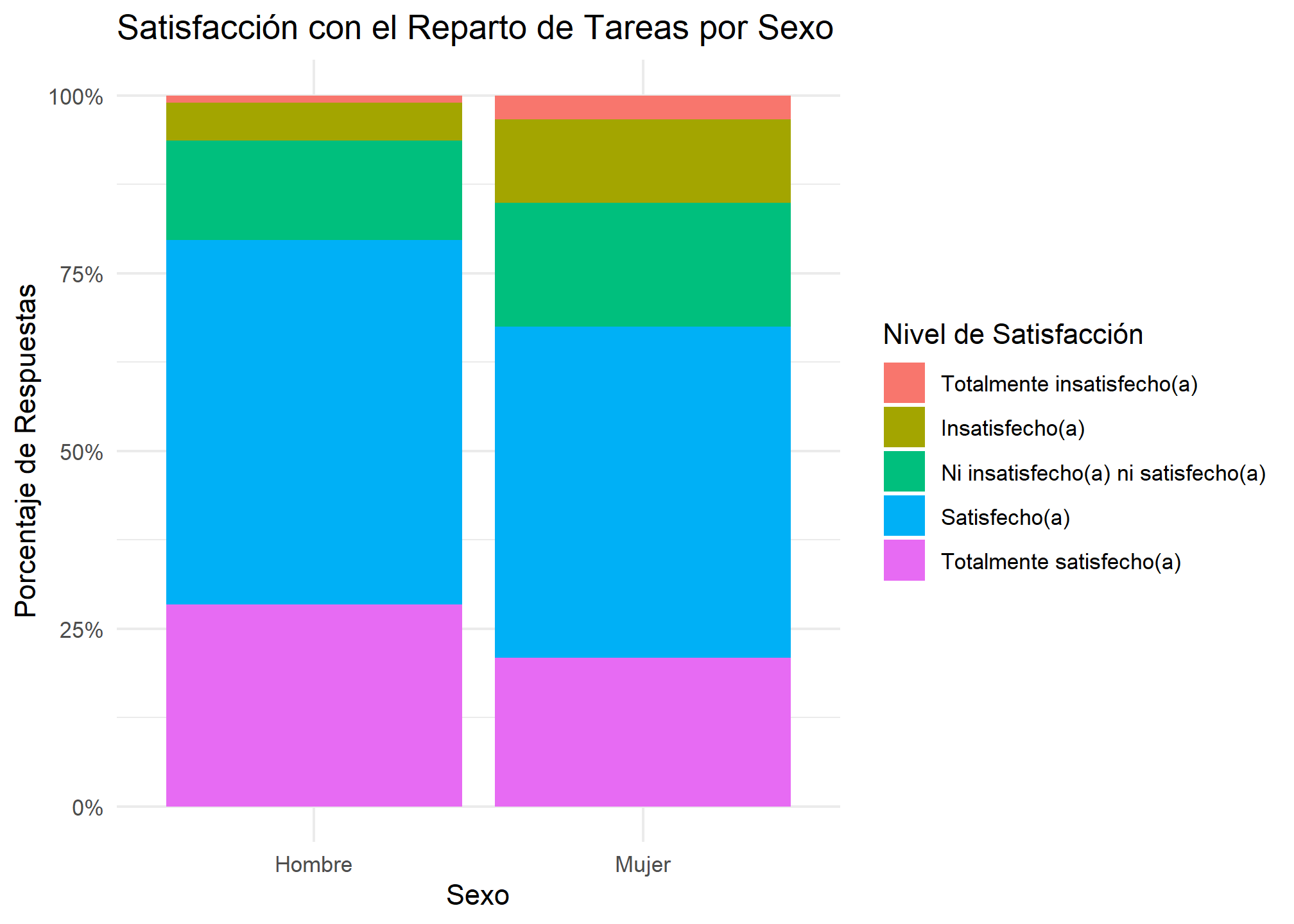
enut_practico %>%
filter(!bs2_factor %in% c("No Aplica", "Valor Perdido") & !is.na(bs2_factor)) %>% # Filtramos NAs
ggplot(aes(x = sexo_factor, fill = bs2_factor, weight = fe_cut)) +
geom_bar(position = "fill") +
scale_y_continuous(labels = scales::percent) +
labs(
title = "Satisfacción con el Reparto de Tareas por Sexo",
x = "Sexo", y = "Porcentaje de Respuestas", fill = "Nivel de Satisfacción"
) +
theme_minimal()
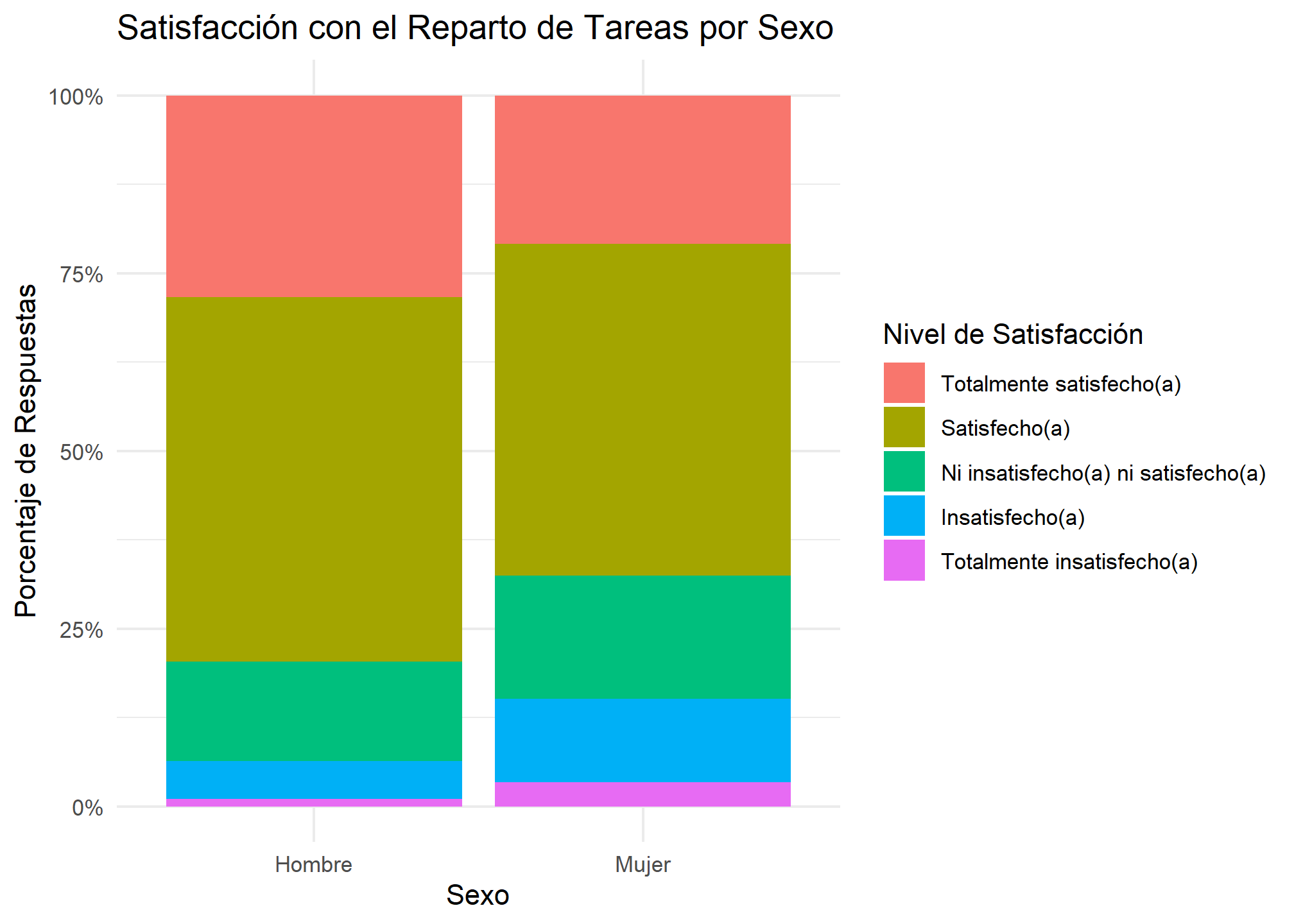
4.2 Flujo 2: Pre-tabular con dplyr y Graficar (geom_col)
Este método da más control y es útil para gráficos complejos.
# Paso 1: Crear una tabla de resumen con los porcentajes
tabla_para_grafico <- enut_practico %>%
filter(!bs2_factor %in% c("No Aplica", "Valor Perdido") & !is.na(bs2_factor)) %>%
count(sexo_factor, bs2_factor, wt = fe_cut) %>%
group_by(sexo_factor) %>%
mutate(porcentaje = n / sum(n))
# Paso 2: Usar geom_col() para graficar los valores pre-calculados
ggplot(tabla_para_grafico, aes(x = sexo_factor, y = porcentaje, fill = fct_rev(bs2_factor))) +
geom_col() + # Usamos geom_col, no geom_bar
scale_y_continuous(labels = scales::percent) +
labs(
title = "Satisfacción con el Reparto de Tareas por Sexo",
x = "Sexo", y = "Porcentaje de Respuestas", fill = "Nivel de Satisfacción"
) +
theme_minimal()
4.3 Actividad 2
Pregunta: Crea un gráfico de barras apiladas al 100% que visualice la relación de la Actividad 1 (nivel educacional vs. condición de actividad). Elige cualquiera de los dos flujos de trabajo. ¿Qué patrón visual confirma lo que viste en la tabla?
# Escribe aquí tu código para la Actividad 2
5. Análisis de Control por Tercera Variable en R
5.1 Control en Tablas usando filter()
Para controlar por una tercera variable en una tabla, simplemente la añadimos a nuestro flujo de dplyr un filtro. La estrategia es filtrar el dataframe para cada categoría de la variable de control y luego construir la tabla de contingencia para ese subgrupo.
Pregunta de investigación: Analicemos la relación entre la condición de actividad (X) y la participación en trabajo de cuidados (Y), pero esta vez controlando por sexo (Z).
# Tabla Parcial 1: Solo para Hombres
enut_practico %>%
filter(sexo_factor == "Hombre") %>%
count(p_tcnr_dt_factor, cae_factor, wt = fe_cut, name = "n_pond") %>%
pivot_wider(names_from = cae_factor, values_from = n_pond) %>%
adorn_totals("row") %>%
adorn_percentages("col") %>%
adorn_pct_formatting(digits = 1) %>%
adorn_ns("front") %>%
kable(caption = "Tabla 1: Participación en Cuidados por Condición de Actividad (Hombres)") %>%
kable_styling(bootstrap_options = "striped", full_width = FALSE)
| p_tcnr_dt_factor | Persona ocupada | Persona desocupada | Personas fuera de la fuerza de trabajo |
|---|---|---|---|
| No | 3,102,858 (63.4%) | 231,206.2 (68.3%) | 1,418,909.8 (77.7%) |
| Sí | 1,788,245 (36.6%) | 107,208.5 (31.7%) | 406,468.9 (22.3%) |
| Total | 4,891,103 (100.0%) | 338,414.7 (100.0%) | 1,825,378.7 (100.0%) |
# Tabla Parcial 2: Solo para Mujeres
enut_practico %>%
filter(sexo_factor == "Mujer") %>%
count(p_tcnr_dt_factor, cae_factor, wt = fe_cut, name = "n_pond") %>%
pivot_wider(names_from = cae_factor, values_from = n_pond) %>%
adorn_totals("row") %>%
adorn_percentages("col") %>%
adorn_pct_formatting(digits = 1) %>%
adorn_ns("front") %>%
kable(caption = "Tabla 1: Participación en Cuidados por Condición de Actividad (Hombres)") %>%
kable_styling(bootstrap_options = "striped", full_width = FALSE)
| p_tcnr_dt_factor | Persona ocupada | Persona desocupada | Personas fuera de la fuerza de trabajo |
|---|---|---|---|
| No | 2,050,628 (52.2%) | 145,738.2 (49.4%) | 2,060,679 (63.3%) |
| Sí | 1,880,488 (47.8%) | 149,137.3 (50.6%) | 1,193,998 (36.7%) |
| Total | 3,931,116 (100.0%) | 294,875.5 (100.0%) | 3,254,677 (100.0%) |
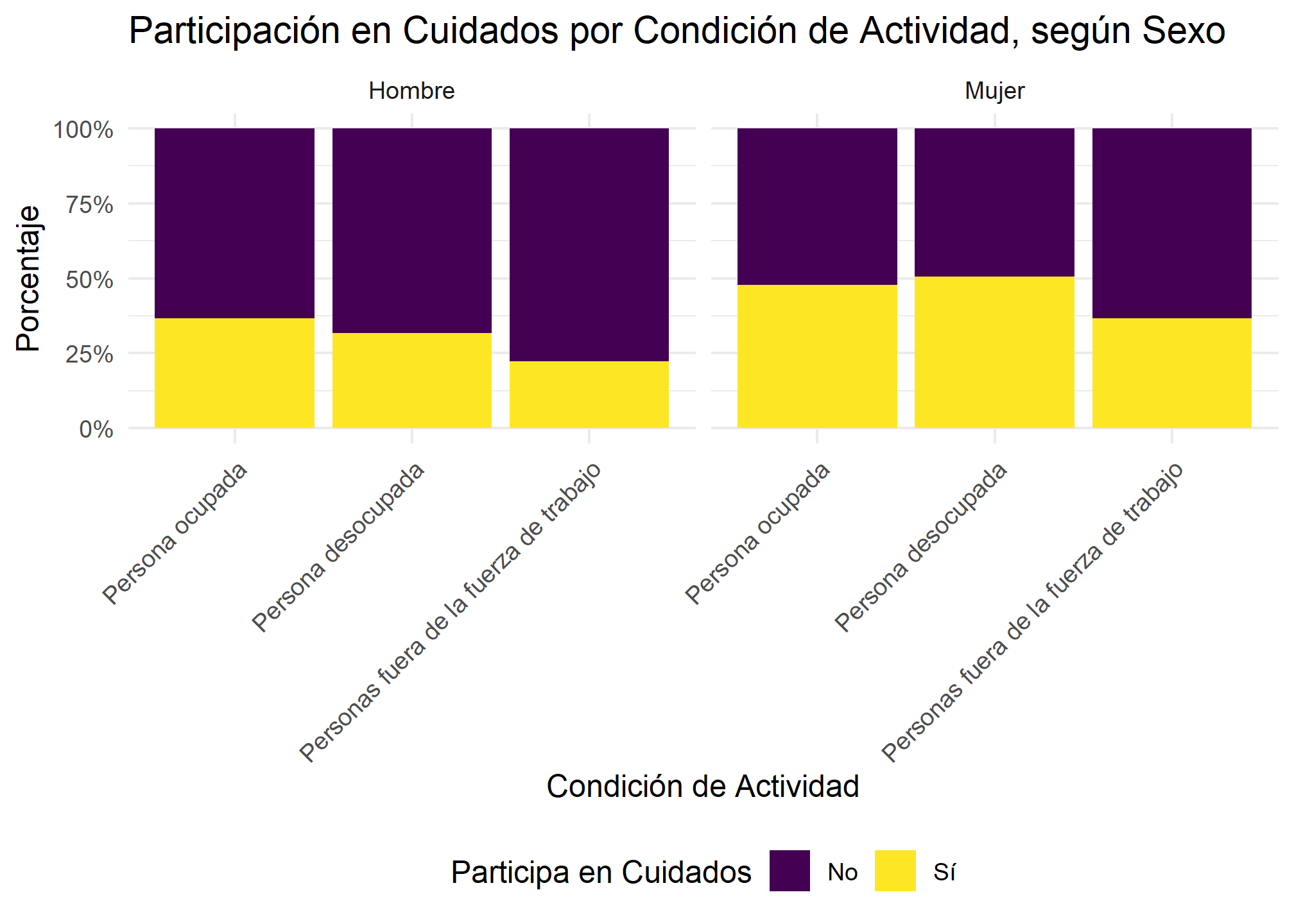
Interpretación: Al estratificar, vemos que la relación cambia. Entre los hombres, las personas ocupadas son quienes más participan en cuidados (36.6%). Entre las mujeres, en cambio, la participación es mayor entre las ocupadas (47.8%), pero también alta entre las fuera de la fuerza de trabajo (36.7%), mostrando patrones diferentes.
5.2 Control en Gráficos con facet_wrap()
facet_wrap() es la contraparte visual de la estratificación, creando un panel para cada categoría de la variable de control de forma automática y mucho más directa.
enut_practico %>%
filter(!is.na(p_tcnr_dt_factor)) %>% # Filtramos NAs para el gráfico
ggplot(aes(x = cae_factor, fill = p_tcnr_dt_factor, weight = fe_cut)) +
geom_bar(position = "fill") +
scale_y_continuous(labels = scales::percent) +
# Añadimos una paleta de colores más atractiva
scale_fill_viridis_d(name = "Participa en Cuidados") +
labs(
title = "Participación en Cuidados por Condición de Actividad, según Sexo",
x = "Condición de Actividad",
y = "Porcentaje"
) +
theme_minimal(base_size = 12) +
theme(axis.text.x = element_text(angle = 45, hjust = 1), legend.position = "bottom") +
# La magia del control: creamos un panel para cada sexo
facet_wrap(~ sexo_factor)
6. Actividad de Desafío Final (Integradora)
Pregunta de Investigación: Se argumenta que la percepción de “falta de tiempo para el descanso” (bs2) está influenciada por la “doble jornada”. Queremos investigar si la relación entre el sexo (X) y la satisfacción con el reparto de tareas (Y) es en realidad un efecto de la condición de actividad (cae_factor) (Z).
- Análisis Bivariado: Crea una tabla de contingencia ponderada (usando el flujo con
dplyryjanitor) con porcentajes de columna para la relación entresexo_factor(X) ybs2_factor(Y). Interprétala brevemente. - Análisis Estratificado: Ahora, controla por
cae_factor. La forma más fácil de hacerlo es congroup_by()antes decount()o usandofacet_wrap()en el gráfico. Elige uno de los dos métodos. - Conclusión: Compara los resultados en los distintos grupos. ¿La brecha de género en la satisfacción con el descanso se mantiene, desaparece o cambia dentro de cada grupo de actividad? Escribe un párrafo de conclusión: ¿La relación original era espuria o se trata de una interacción/especificación?
# 1. Código para el análisis bivariado
# 2. Código para el análisis estratificado
# 3. Párrafo de conclusión (como comentario)