Introducción al Análisis Bivariado: Explorando el Uso del Tiempo con la ENUT 2023
0. Objetivos del Práctico
El objetivo de este práctico es aplicar el marco de análisis bivariado para explorar relaciones entre variables en la Encuesta Nacional de Uso del Tiempo (ENUT) 2023. Al finalizar, serás capaz de:
- Aplicar el flujo de trabajo para cada uno de los tres tipos de relaciones (Categórica-Cuantitativa, Categórica-Categórica, Cuantitativa-Cuantitativa).
- Dominar el uso de
group_by()ysummarise()como herramientas centrales para la comparación de grupos. - Utilizar el factor de expansión
fe_cutpara obtener estimaciones poblacionales válidas. - Interpretar tablas de resumen y visualizaciones bivariadas en el contexto del uso del tiempo y las desigualdades de género.
1. Contexto y Preparación: La Encuesta Nacional de Uso del Tiempo (ENUT)
1.1 El “Porqué” de la ENUT
El tiempo es un recurso universal, pero su distribución y uso no lo son. Gran parte del trabajo que sostiene a la sociedad, como las tareas domésticas y de cuidados, es trabajo no remunerado, históricamente invisibilizado y feminizado. La Encuesta Nacional de Uso del Tiempo (ENUT) es la principal herramienta en Chile para medir este fenómeno, haciendo visible lo invisible para el diseño de políticas públicas más equitativas.
1.2 Variables Clave y el “Día Tipo”
En este práctico, nos enfocaremos en las variables de “Día Tipo”, que representan un promedio ponderado del tiempo dedicado a una actividad: (tiempo en día de semana * 5 + tiempo en día de fin de semana * 2) / 7.
t_to_dt: Trabajo en la Ocupación (remunerado).t_tdnr_dt: Trabajo Doméstico No Remunerado.t_tcnr_dt: Trabajo de Cuidados No Remunerado.
1.3 Preparación del Entorno
# Cargar paquetes
library(tidyverse)
library(haven)
library(DescTools) # Para estadísticos ponderados
library(rio) # Para importar datos fácilmente
library(knitr)
library(kableExtra)
# Carga Manual (Método recomendado)
# 1. Crea una carpeta 'datos' en tu Proyecto de RStudio.
# 2. Descarga el archivo .zip desde: https://www.ine.gob.cl/docs/default-source/uso-del-tiempo-tiempo-libre/bbdd/ii-enut/250403-ii-enut-bdd-r-v2.zip?sfvrsn=87682f16_7
# 3. Guarda el archivo .zip en tu carpeta 'datos'.
# 4. Ejecuta el siguiente código:
enut <- rio::import("datos/250403-ii-enut-bdd-r-v2.zip", which = "250403-ii-enut-bdd-r-v2.RDS")
El siguiente bloque carga los datos automáticamente para la reproducibilidad del documento.
# Carga automática de datos
enut <- rio::import("https://www.ine.gob.cl/docs/default-source/uso-del-tiempo-tiempo-libre/bbdd/ii-enut/250403-ii-enut-bdd-r-v2.zip?sfvrsn=87682f16_7", which = "250403-ii-enut-bdd-r-v2.RDS")
1.4 Limpieza Inicial de Datos
Preparamos nuestra base de trabajo.
# Filtramos, limpiamos NAs y creamos variables factoriales
enut_trabajo <- enut %>%
filter(tiempo == 1) %>% # Nos quedamos solo con quienes contestaron el cuestionario de uso tiempo
mutate(
# Reemplazamos el código de 'no aplica' (96) por NA
t_tnr_dt = na_if(t_tnr_dt, 96),
t_tcnr_dt = na_if(t_tcnr_dt, 96),
t_to_dt = na_if(t_to_dt, 96),
t_tdnr_dt = na_if(t_tdnr_dt, 96),
# Creamos variables factor para análisis
sexo_factor = as_factor(sexo),
nivel_educ_factor = as_factor(nivel_educ),
bs2_factor = as_factor(bs2)
)
2. Categórica (X) ➞ Cuantitativa (Y): La Brecha de Género
2.1 La Lógica de group_by(): El Motor de la Comparación
group_by() es la función clave que transforma nuestras herramientas univariadas en bivariadas. No cambia los datos visiblemente, sino que le dice a dplyr que cualquier operación posterior (como summarise) debe realizarse por separado para cada grupo definido.
2.2 Análisis Numérico
Pregunta: ¿Cómo difieren las horas de trabajo no remunerado (doméstico y de cuidados) entre hombres y mujeres?
tabla_caso1 <- enut_trabajo %>%
group_by(sexo_factor) %>%
summarise(
Media_TDNR = weighted.mean(t_tdnr_dt, w = fe_cut, na.rm = TRUE),
Mediana_TDNR = Median(t_tdnr_dt, weights = fe_cut, na.rm = TRUE),
Media_TCNR = weighted.mean(t_tcnr_dt, w = fe_cut, na.rm = TRUE),
Mediana_TCNR = Median(t_tcnr_dt, weights = fe_cut, na.rm = TRUE)
)
knitr::kable(tabla_caso1, digits = 2)
| sexo_factor | Media_TDNR | Mediana_TDNR | Media_TCNR | Mediana_TCNR |
|---|---|---|---|---|
| Hombre | 2.15 | 1.6 | 1.49 | 0.93 |
| Mujer | 3.52 | 3.1 | 2.28 | 1.49 |
Interpretación: La tabla muestra una fuerte brecha de género. En promedio, las mujeres dedican casi el doble de horas al trabajo doméstico (3.52 vs. 2.15) y al trabajo de cuidados (1.93 vs. 1.05) que los hombres.
2.3 Análisis Visual
# Boxplots comparativos para el trabajo doméstico no remunerado
ggplot(enut_trabajo, aes(x = sexo_factor, y = t_tnr_dt, fill = sexo_factor)) +
geom_boxplot(outlier.alpha = 0.1) +
labs(
title = "Distribución de Horas de Trabajo No Remunerado por Sexo",
x = "Sexo", y = "Horas diarias"
) +
theme_minimal() +
theme(legend.position = "none")
## Warning: Removed 918 rows containing non-finite outside the scale range
## (`stat_boxplot()`).
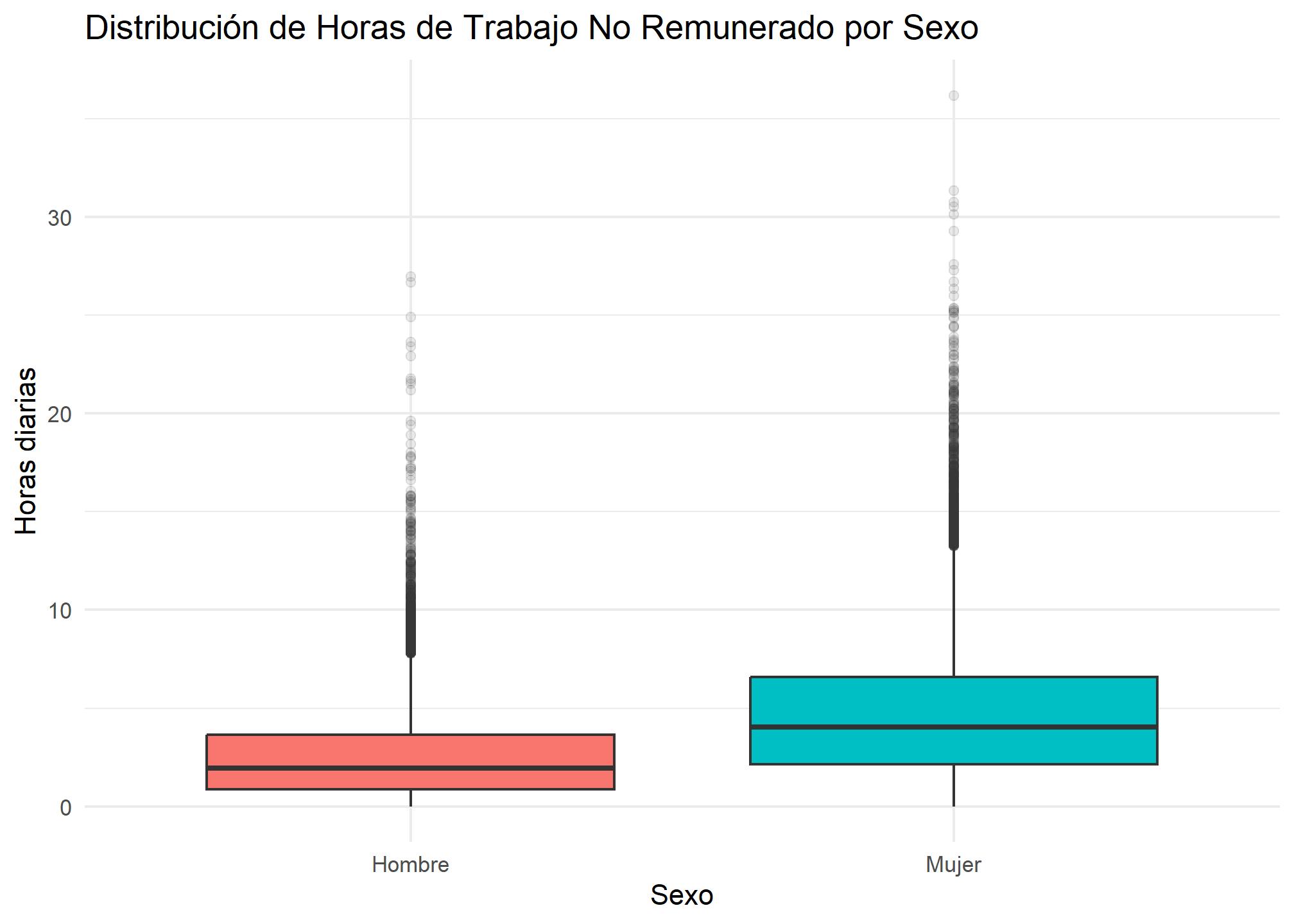
Interpretación: La mediana de las mujeres es superior al tercer cuartil de los hombres. Esto significa que más del 50% de las mujeres dedica más tiempo a tareas domésticas que el 75% de los hombres.
2.4 Actividad 1
Pregunta: Analiza la relación entre el Nivel Socioeconómico (NSE) y el tiempo dedicado al trabajo remunerado (t_to_dt). ¿Existen diferencias en el promedio de horas de trabajo remunerado entre los distintos NSE? Realiza un análisis numérico (tabla con medias y medianas ponderadas) y uno visual (boxplots comparativos).
# Escribe aquí tu código para el análisis numérico (tabla)
# Escribe aquí tu código para el análisis visual (boxplot)
3. Categórica (X) ➞ Categórica (Y): Satisfacción y Género
3.1 Análisis Numérico con dplyr
Pregunta: ¿Se asocia el sexo (X) con la satisfacción con el reparto de tareas domésticas (bs2, Y)?
Para responder, construiremos una tabla de contingencia que muestre cómo se distribuye la satisfacción dentro de cada sexo, calculando los porcentajes de columna.
# 1. Creamos y limpiamos las variables factoriales que usaremos
enut_limpio_cat <- enut_trabajo %>%
mutate(
bs2_factor = as_factor(bs2)
) %>%
filter(!is.na(sexo_factor), !is.na(bs2_factor), !bs2_factor %in% c("No Aplica", "Valor Perdido"))
# 2. Construimos la tabla de porcentajes de columna
tabla_catcat <- enut_limpio_cat %>%
# Agrupamos por la variable explicativa (sexo)
group_by(sexo_factor) %>%
# Contamos las combinaciones, usando el ponderador
count(bs2_factor, wt = fe_cut, name = "n") %>%
# Calculamos el porcentaje que cada celda representa del total de su columna (grupo)
mutate(Porcentaje = n / sum(n) * 100) %>%
# Seleccionamos y pivoteamos para la presentación final
select(sexo_factor, bs2_factor, Porcentaje) %>%
pivot_wider(names_from = sexo_factor, values_from = Porcentaje)
# 3. Presentamos la tabla con kable()
knitr::kable(
tabla_catcat,
digits = 1,
caption = "Satisfacción con el reparto de tareas por sexo (%)"
) %>%
kable_styling(bootstrap_options = "striped", full_width = FALSE)
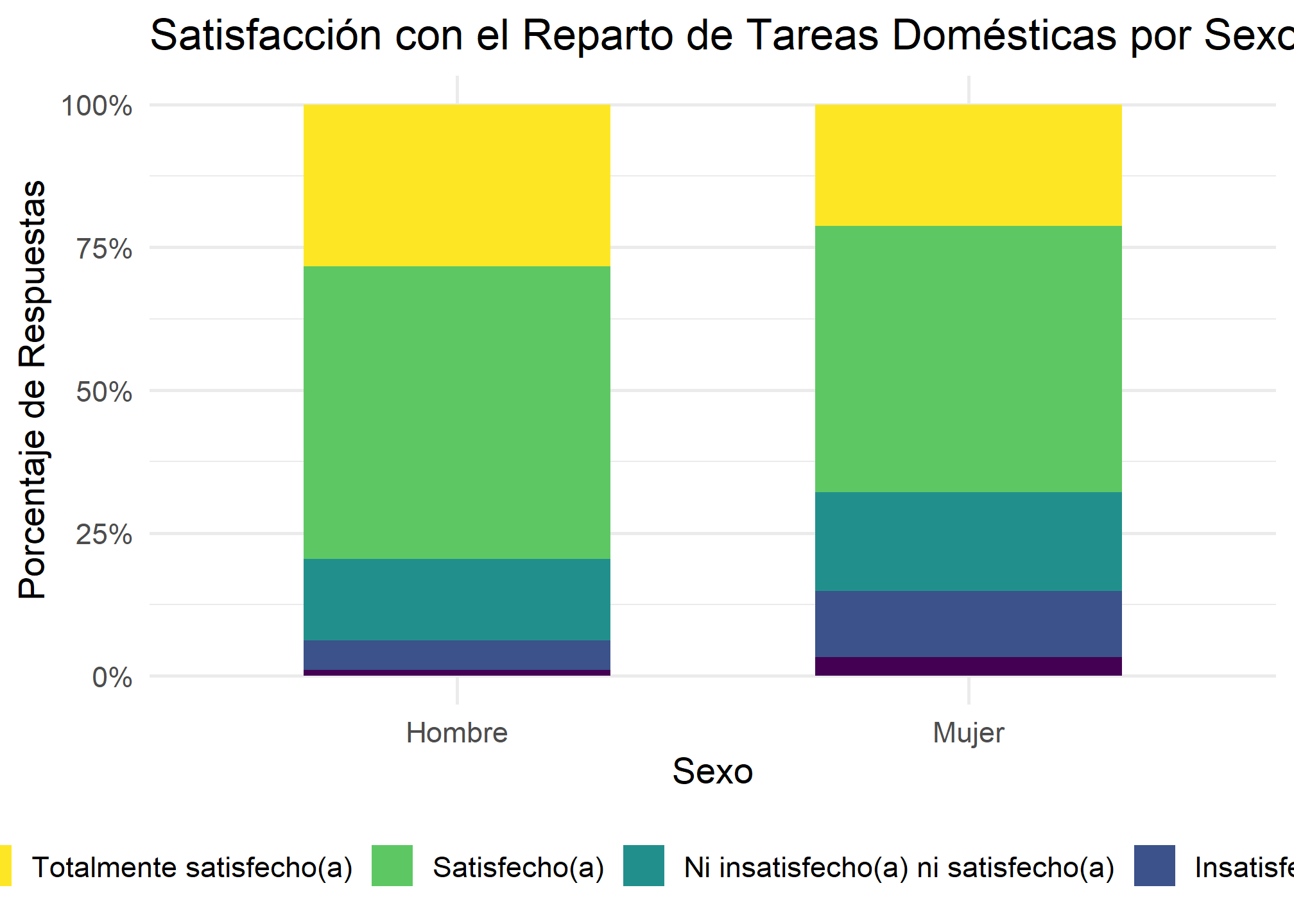
| bs2_factor | Hombre | Mujer |
|---|---|---|
| Totalmente insatisfecho(a) | 1.0 | 3.3 |
| Insatisfecho(a) | 5.2 | 11.5 |
| Ni insatisfecho(a) ni satisfecho(a) | 14.2 | 17.3 |
| Satisfecho(a) | 51.2 | 46.7 |
| Totalmente satisfecho(a) | 28.3 | 21.2 |
Interpretación: La tabla revela una clara diferencia de género en la satisfacción. Mientras que un 28.3% de los hombres se declara “Totalmente satisfecho(a)”, solo un 21.2% de las mujeres lo hace. Por el contrario, la insatisfacción (sumando “Insatisfecho(a)” y “Totalmente insatisfecho(a)") es mucho mayor en mujeres (14.8%) que en hombres (6.2%).
3.2 Análisis Visual
El gráfico de barras apiladas al 100% visualiza directamente los porcentajes que calculamos.
enut_limpio_cat %>%
ggplot(aes(x = sexo_factor, fill = fct_rev(bs2_factor), weight = fe_cut)) +
geom_bar(position = "fill", width = 0.6) +
scale_y_continuous(labels = scales::percent) +
scale_fill_viridis_d(option = "viridis", direction = -1) +
labs(
title = "Satisfacción con el Reparto de Tareas Domésticas por Sexo",
x = "Sexo",
y = "Porcentaje de Respuestas",
fill = "Nivel de Satisfacción"
) +
theme_minimal(base_size = 14) +
theme(legend.position = "bottom")
3.3 Actividad 2
Pregunta: ¿Existe una relación entre la Condición de Actividad (cae) y la Participación en Trabajo de Cuidados no Remunerado (p_tcnr_dt)? Crea una tabla de contingencia ponderada con porcentajes de fila e interprétala.
# Escribe aquí tu código para la tabla de contingencia
4. Cuantitativa (X) ➞ Cuantitativa (Y): Edad y Trabajo Doméstico
4.1 Análisis Visual
Pregunta: ¿Cómo se relaciona la edad con el tiempo dedicado al trabajo doméstico (t_tdnr_dt)?
ggplot(enut_trabajo, aes(x = edad, y = t_tdnr_dt)) +
geom_point(alpha = 0.05, color = "#008080", position = "jitter") +
geom_smooth(color = "red", se = FALSE, method = "loess") +
geom_smooth(color = "blue", se = FALSE, method = "lm") +
labs(
title = "Horas de Trabajo Doméstico No Remunerado según Edad",
x = "Edad", y = "Horas diarias de trabajo no remunerado"
) +
theme_minimal()
## `geom_smooth()` using formula = 'y ~ x'
## `geom_smooth()` using formula = 'y ~ x'
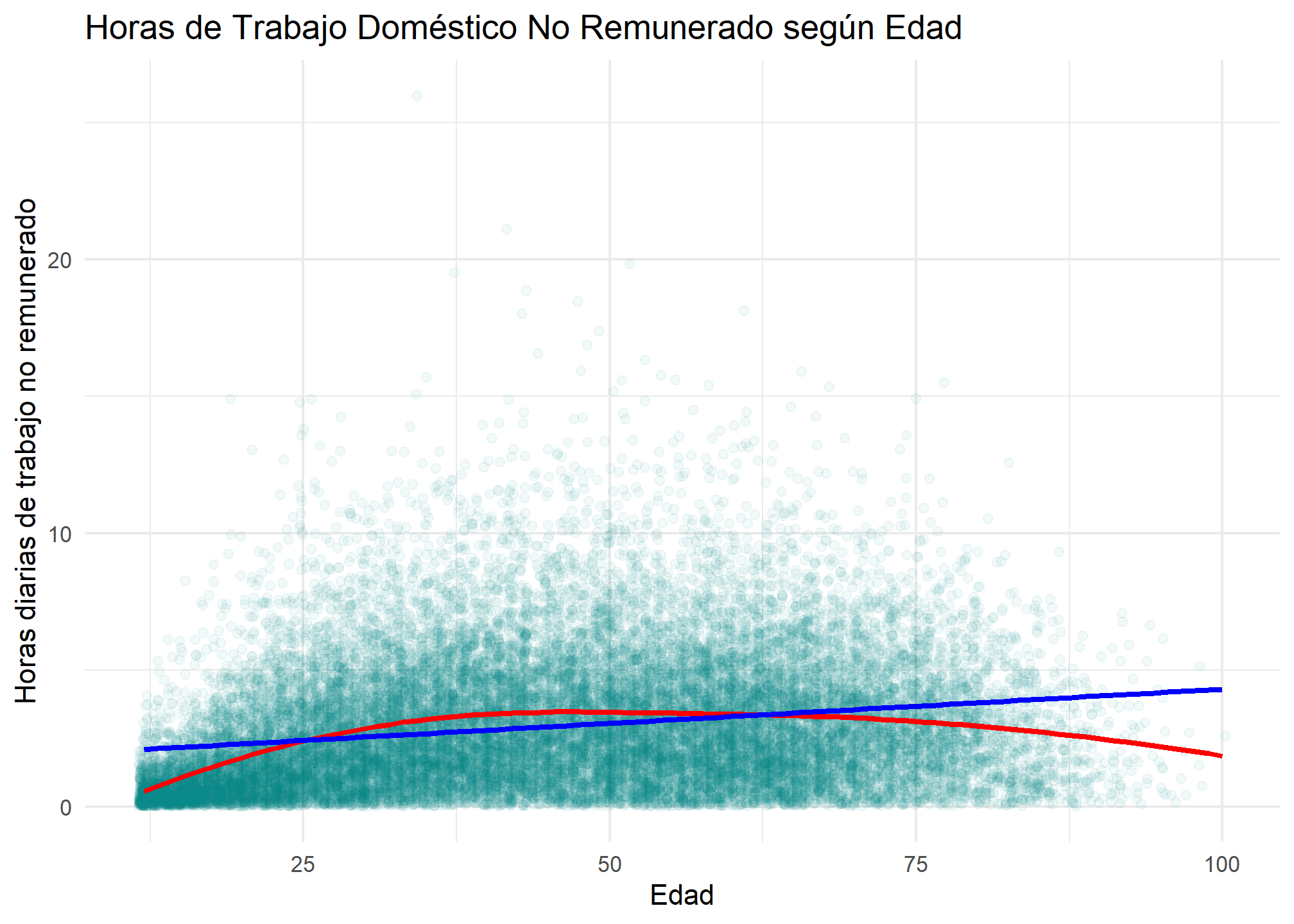
Interpretación: La relación es curvilínea. El tiempo aumenta hasta la adultez media y luego disminuye. La correlación representa la relación lineal (linea azul).
4.2 Análisis Numérico
Calculamos la correlación para cuantificar la parte lineal de la relación.
cor(enut_trabajo$edad, enut_trabajo$t_tdnr_dt, use = "pairwise.complete.obs")
## [1] 0.204062
Interpretación: La correlación es 0.2, un valor bajo que confirma que la relación no es lineal, como ya habíamos visto en el gráfico.
4.3 Actividad 3
Pregunta: Explora la relación entre las horas de trabajo remunerado (t_to_dt) y las horas de trabajo doméstico (t_tdnr_dt). ¿Esperarías una relación positiva, negativa o nula? Crea un gráfico de dispersión y calcula la correlación para comprobar tu hipótesis.
# Escribe aquí tu código para el gráfico de dispersión y la correlación
5. Actividad de Desafío Final (Integradora)
Pregunta: Como sociólogo/a, quieres investigar la ‘doble jornada’. La hipótesis es que las mujeres que trabajan más horas de forma remunerada no ven una disminución proporcional en su trabajo doméstico no remunerado.
- Filtra la base de datos para quedarte solo con las mujeres ocupadas
(sexo == 2 & cae == 2). - Crea un gráfico de dispersión que muestre la relación entre las horas de trabajo en la ocupación (
t_to_dt, eje X) y las horas de trabajo doméstico no remunerado (t_tdnr_dt, eje Y). Añade una línea de tendencia. - Calcula la correlación entre estas dos variables para este subgrupo.
- Escribe un párrafo de interpretación final: ¿Qué te dicen el gráfico y la correlación sobre la hipótesis de la ‘doble jornada’ para las mujeres ocupadas en Chile?
# Escribe aquí tu código para el desafío final