Descripción de Variables Categóricas: Frecuencias y Gráficos de Barras en R
0. Objetivos del Práctico
El objetivo de este práctico es aplicar los conceptos de descripción de variables categóricas vistos en clase, utilizando R para el análisis. Al finalizar, serás capaz de:
- Importar una base de datos en formato Stata (
.dta). - Generar e interpretar tablas de frecuencias (absolutas y porcentuales) usando R base y
dplyr, considerando los factores de expansión. - Crear tablas de presentación estéticas con el paquete
knitr. - Visualizar la distribución de una variable categórica usando gráficos de barras, tanto con R base como con
ggplot2.
1. Contexto: La Encuesta Nacional de Empleo (ENE)
La Encuesta Nacional de Empleo (ENE), realizada por el Instituto Nacional de Estadísticas (INE), es el principal instrumento para medir el mercado laboral en Chile. Sus datos se publican mensualmente y son fundamentales para el diagnóstico económico y social del país.
Hoy trabajaremos con los datos del trimestre móvil Junio-Julio-Agosto de 2025, y nos enfocaremos en la variable activ, que mide la condición de actividad de las personas.
2. Preparación del Entorno y Carga de Datos
2.1 Configuración del Proyecto y Descarga de Datos
- Crea un Proyecto de RStudio y una carpeta
datosdentro de él. - Descarga la base de datos desde el sitio del INE. El archivo está en formato Stata (
.dta). - Guarda el archivo: Guarda el archivo
ene-2025-07-jja.dtadentro de tu carpetadatos.
2.2 Carga de Paquetes
library(haven)
library(tidyverse) #incluye ggplot2
library(knitr)
library(kableExtra)
2.3 Carga de la Base de Datos
Vamos a cargar los datos usando read_dta() del paquete haven, ya que es un archivo de Stata.
# Cargar la base de datos de la ENE desde tu carpeta local
ene <- haven::read_dta("datos/ene-2025-07-jja.dta")
Nota sobre la reproducibilidad: Para que este práctico funcione de manera autocontenida, a continuación se incluye el código que realiza la descarga y carga de forma automática.
# Este código cargará automáticamente los datos desde la web
temp <- tempfile(fileext = ".dta")
download.file("https://www.ine.gob.cl/docs/default-source/ocupacion-y-desocupacion/bbdd/2025/stata/ene-2025-07-jja.dta?sfvrsn=3f9c9348_5&download=true", temp, mode="wb")
ene <- haven::read_dta(temp)
unlink(temp); remove(temp)
knitr::opts_knit$set(bookdown.internal.label = FALSE)
3. Tablas de Frecuencia
El primer paso para describir una variable categórica es crear una tabla de frecuencias. Veremos diferentes formas de hacerlo, prestando atención a si estamos describiendo solo la muestra o estimando para la población.
3.1 Con R Base: table() y prop.table() (Descripción de la Muestra)
Las funciones de R base table() y prop.table() son excelentes para una exploración rápida de la muestra, pero no incorporan los factores de expansión.
# Primero, creamos la variable factor para que sea legible
ene$condicion_actividad <- as_factor(ene$activ)
# Frecuencias absolutas de la muestra
frec_abs_muestra <- table(ene$condicion_actividad)
frec_abs_muestra
##
## Ocupados/as Desocupados/as
## 42467 3918
## Fuera de la fuerza de trabajo
## 36286
# Frecuencias relativas (porcentajes) de la muestra
prop.table(frec_abs_muestra) * 100
##
## Ocupados/as Desocupados/as
## 51.368678 4.739268
## Fuera de la fuerza de trabajo
## 43.892054
Interpretación: Es un método rápido, pero requiere dos pasos y el resultado es menos prolijo que con otras alternativas. Estos resultados nos describen la composición de los datos que tenemos en R, pero no son una estimación correcta de la población chilena porque no están ponderados.
3.2 Con dplyr: Estimando para la Población
Para obtener estimaciones poblacionales, debemos usar el factor de expansión (en la ENE, se llama fact_cal). El flujo de dplyr nos permite incorporar este peso de manera muy sencilla.
Importante: La condición de actividad se mide para la población en edad de trabajar (15 años o más). Por lo tanto, debemos filtrar la base antes de hacer los cálculos.
# Explicación del código:
# 1. Filtramos para quedarnos solo con las personas de 15 años o más.
# 2. count() ahora tiene el argumento `wt = fact_cal`. Esto le dice a R que, en lugar de contar cada fila como 1, debe sumar el valor de la columna 'fact_cal'. El resultado es una estimación del número total de personas en la población.
# 3. mutate() crea una nueva columna 'Porcentaje'. Para calcularla:
# - Dividimos la frecuencia de cada fila (Frecuencia_Absoluta) por el total de casos (sum(Frecuencia_Absoluta)).
# - Multiplicamos por 100 para obtener el porcentaje.
tabla_frec_pob <- ene %>%
filter(edad >= 15) %>%
count(condicion_actividad, wt = fact_cal, name = "Poblacion_Estimada") %>%
mutate(
Porcentaje = (Poblacion_Estimada / sum(Poblacion_Estimada)) * 100
)
tabla_frec_pob
## # A tibble: 3 × 3
## condicion_actividad Poblacion_Estimada Porcentaje
## <fct> <dbl> <dbl>
## 1 Ocupados/as 9355097. 56.5
## 2 Desocupados/as 875888. 5.29
## 3 Fuera de la fuerza de trabajo 6312197. 38.2
4. Presentando Tablas con knitr::kable()
Presentemos la tabla de forma limpia y profesional: kable() crea la tabla a partir del data frame (aplica formato y el caption) y kable_styling() le da el aspecto visual (estilos HTML) para que se vea bien en el Viewer de RStudio.
kable(
tabla_frec_pob,
digits = c(0, 0, 1),
col.names = c("Condición de Actividad", "Población Estimada", "Porcentaje (%)"),
caption = "Estimación de la Condición de Actividad (Población 15 años y más, ponderada)"
) |>
kable_styling()
| Condición de Actividad | Población Estimada | Porcentaje (%) |
|---|---|---|
| Ocupados/as | 9355097 | 56.5 |
| Desocupados/as | 875888 | 5.3 |
| Fuera de la fuerza de trabajo | 6312197 | 38.2 |
Interpretación: Esta tabla es una estimación para la población total de Chile. Ahora sí podemos decir que, para este trimestre, se estima que un 56.5% de la población en edad de trabajar estaba ocupada. Estos son los números que se acercan a las cifras oficiales del INE.
5. Visualización: Gráficos de Barras
Ahora, vamos a visualizar la información, manteniendo la distinción entre muestra y población.
5.1 Gráfico de Barras con R Base (Descripción de la Muestra)
barplot() trabaja con tablas pre-calculadas. Por defecto, no tiene un argumento simple para ponderar, por lo que lo usaremos para visualizar las frecuencias de la muestra. Es una herramienta rápida para una exploración inicial.
# 1. Creamos la tabla de frecuencias de la muestra (mayores de 15)
frecuencias_muestra <- table(ene$condicion_actividad[ene$edad >= 15])
# 2. Creamos el gráfico, explicando sus argumentos
barplot(
height = frecuencias_muestra, # Altura de las barras
main = "Distribución de la Muestra por Condición de Actividad",
xlab = "Condición de Actividad",
ylab = "Frecuencia (conteo de la muestra)",
col = "#D76D77",
ylim = c(0, 50000)
)
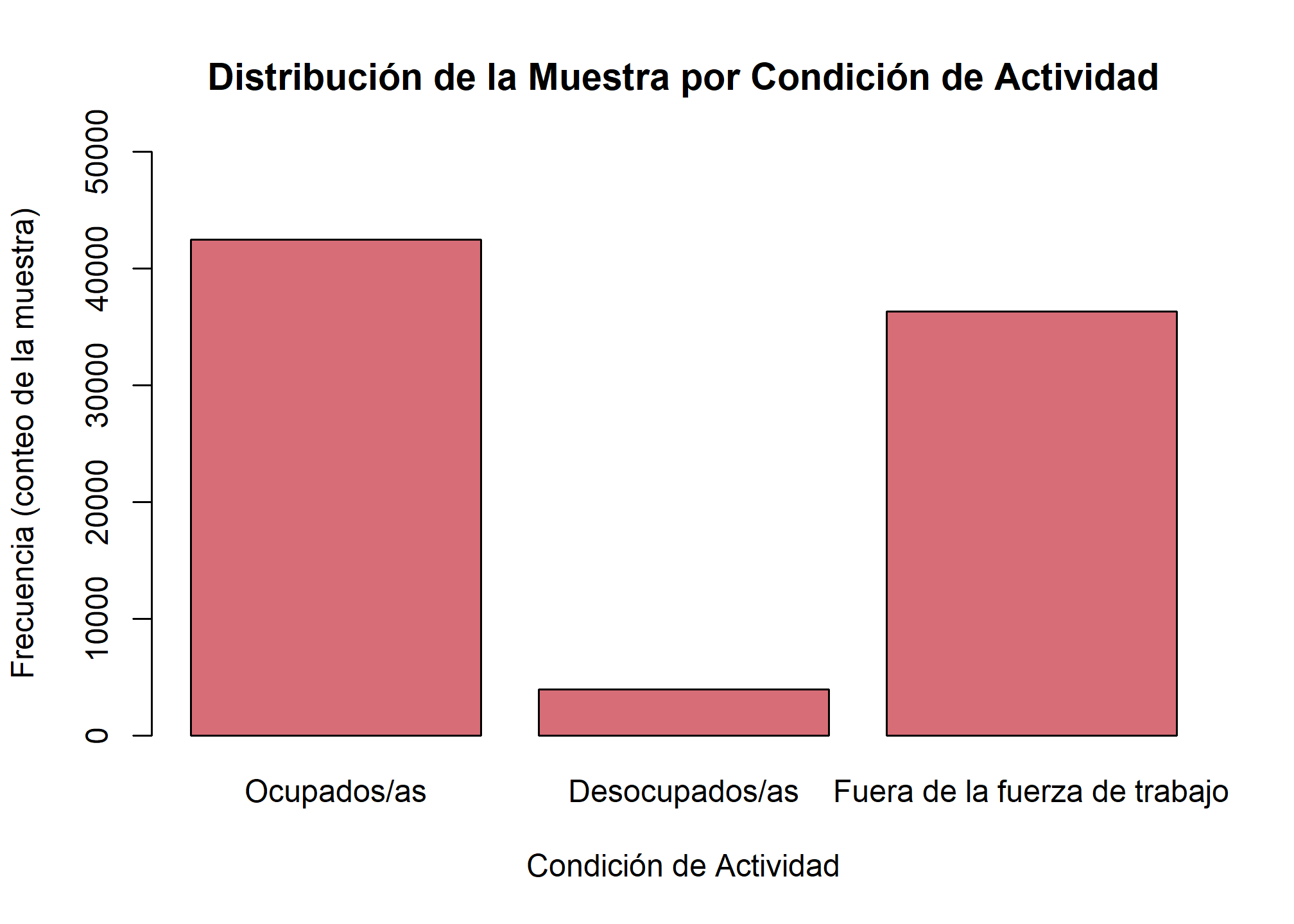 Análisis: El gráfico nos da una idea visual rápida de las magnitudes, sin ponderar. Su principal ventaja es la simplicidad y la velocidad, pero su personalización es menos intuitiva que con
Análisis: El gráfico nos da una idea visual rápida de las magnitudes, sin ponderar. Su principal ventaja es la simplicidad y la velocidad, pero su personalización es menos intuitiva que con ggplot2.
5.2 Gráfico de Barras con ggplot2 (Estimación para la Población)
ggplot2 nos permite construir gráficos por capas, dándonos un control total. geom_bar() puede calcular las frecuencias por nosotros directamente desde los datos e incorporar los ponderadores directamente en la construcción del gráfico a través del argumento weight.
# Explicación del código:
# 1. ggplot(data, aes(x)): Iniciamos el gráfico, definimos los datos y el mapeo estético principal (qué va en el eje x). En `aes()`, además de `x`, añadimos `weight = fact_cal`. Esto le dice a ggplot2
# 2. geom_bar(): Añadimos la capa geométrica. Al no especificar un eje 'y', `geom_bar` cuenta automáticamente los casos por cada categoría de 'x'.
# 3. labs(): Añadimos las etiquetas, títulos y fuentes.
ene %>%
filter(edad >= 15) %>%
ggplot(aes(x = condicion_actividad, weight = fact_cal)) +
geom_bar(fill = "#3A1C71") +
labs(
title = "Estimación de la Condición de Actividad en la Población",
subtitle = "Trimestre Junio-Julio-Agosto 2025",
x = "Condición de Actividad",
y = "Población Estimada",
caption = "Fuente: ENE"
) +
theme_minimal()
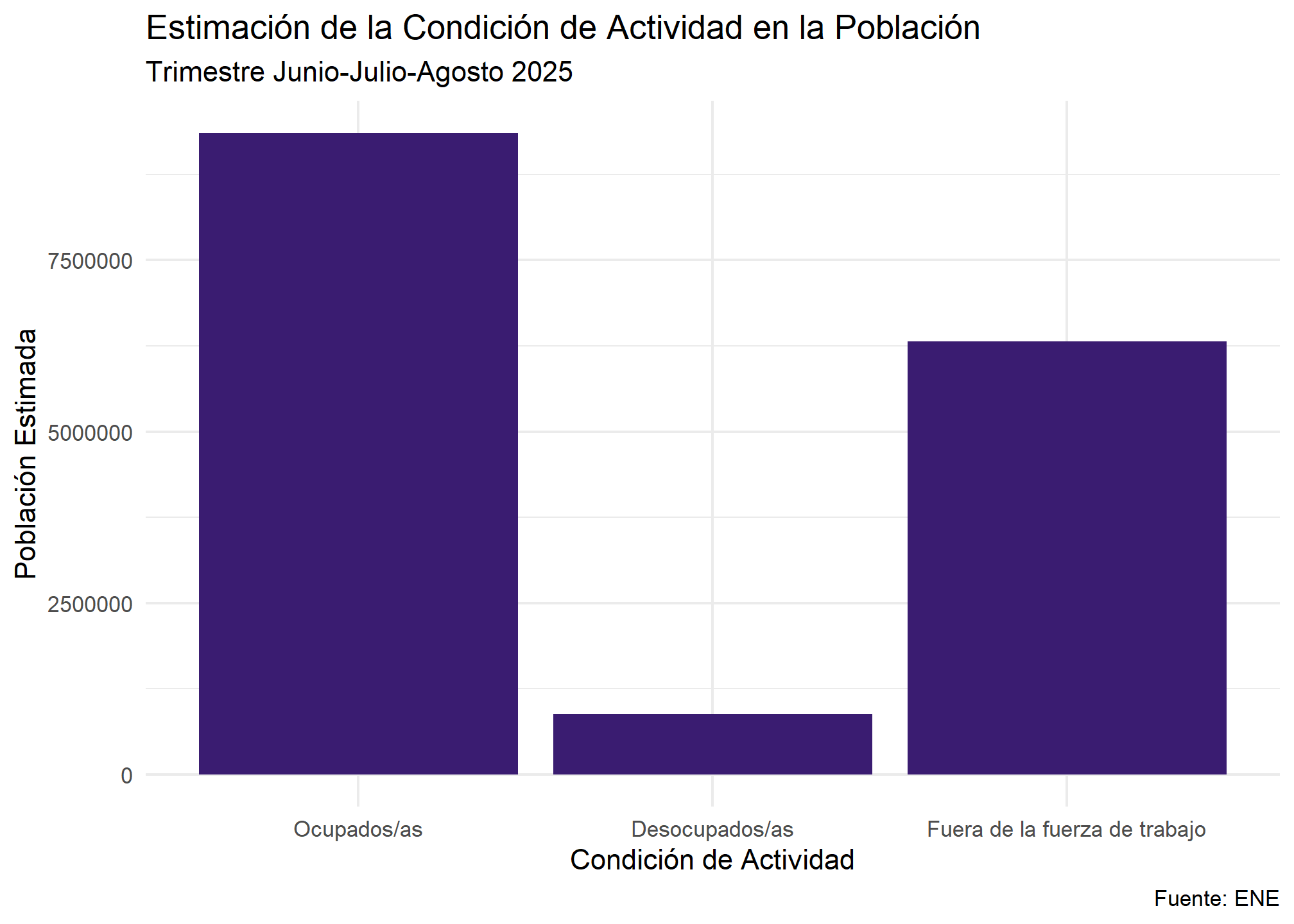 Análisis: Este gráfico es una representación visual de las estimaciones poblacionales. La altura de las barras representa el número total de personas que se estima hay en cada categoría en todo el país.
Análisis: Este gráfico es una representación visual de las estimaciones poblacionales. La altura de las barras representa el número total de personas que se estima hay en cada categoría en todo el país.
6. Actividad de Desafío
- Crear una tabla de frecuencias completa: Usando el flujo de
dplyryknitr::kable(), crea una tabla de frecuencias para la variableregionde la encuesta ENE. Usar el factor de expansiónfact_cal.Asegúrate de incluir frecuencias absolutas y porcentajes. - Crear un gráfico de barras: Usando
ggplot2, crea un gráfico de barras que muestre la distribución de personas porregion.- Pista 1: No olvides filtrar por edad y usar
aes(weight = fact_cal). - Pista 2: Para que el eje X sea legible, puedes usar
+ theme(axis.text.x = element_text(angle = 45, hjust = 1))para rotar las etiquetas de las regiones.
- Pista 1: No olvides filtrar por edad y usar
# Escribe tu código para la tabla aquí
# Escribe tu código para el gráfico aquí