Construcción y Combinación de Datos: Un Análisis de Bienestar Infantil con la ELPI
0. Objetivos del Práctico
El objetivo de este práctico es aplicar las técnicas avanzadas de manipulación de datos vistas en clase. Al finalizar, serás capaz de:
- Manejar un proyecto con múltiples bases de datos en diferentes formatos.
- Aplicar
left_join()para combinar información de diferentes fuentes (cuidador y niño/a). - Realizar recodificaciones complejas usando
case_when()para crear una tipología. - Construir un índice sumativo a partir de múltiples indicadores.
- Aplicar un flujo de trabajo completo para limpiar, preparar y analizar los datos, respondiendo a una pregunta de investigación.
1. Contexto: La Encuesta Longitudinal de Primera Infancia (ELPI)
La Encuesta Longitudinal de Primera Infancia (ELPI) es un estudio a nivel nacional que sigue a una cohorte de niños y niñas desde su nacimiento para monitorear su desarrollo en el tiempo. Es una herramienta fundamental para el diseño y evaluación de políticas públicas en el área de la niñez en Chile.
La ELPI recolecta información de diferentes fuentes y a través de distintos cuestionarios. Hoy trabajaremos con dos de ellos de la ronda 2017:
- La base del Cuidador Principal, que contiene información socioeconómica detallada del hogar.
- La base de Niños y Niñas, que contiene las respuestas de un cuestionario auto-aplicado contestado por los niños y niñas de 7 años o más.
Nuestro primer desafío será unir estas dos fuentes para poder analizar cómo las características del hogar se relacionan con el bienestar de los niños/as.
2. Preparación del Entorno y Carga de Datos
2.1 Configuración del Proyecto y Descarga de Datos
Como siempre, un flujo de trabajo reproducible comienza con una buena organización.
- Crea un Proyecto de RStudio: Si aún no lo has hecho, crea un nuevo Proyecto para esta unidad.
- Crea una carpeta de datos: Dentro de tu proyecto, crea una carpeta llamada
datos. - Descarga las bases de datos:
- Guarda los archivos: Descomprime los archivos
.zipy guarda los archivos.dtay.savdentro de tu carpetadatos.
2.2 Carga de Paquetes
Cargamos los paquetes que usaremos hoy. haven es esencial porque nos permite leer datos de otros software estadísticos como Stata y SPSS.
library(haven)
library(tidyverse)
2.3 Carga de las Bases de Datos desde Archivos Locales
Ahora, cargaremos los datos en R. Fíjate que usamos una función diferente para cada tipo de archivo: read_dta() para Stata y read_sav() para SPSS.
# Cargar la base de datos del Cuidador Principal (formato Stata)
elpicp <- haven::read_dta("datos/Base_Cuidador_Principal_ELPI_III(STATA)_241010.dta")
# Cargar la base de datos de Niños y Niñas (formato SPSS)
elpinna <- haven::read_sav("datos/Base Niños y Niñas ELPI III (SPSS).sav")
Nota sobre la reproducibilidad: Para que este práctico funcione de manera autocontenida, a continuación se incluye el código que realiza la descarga y carga de forma automática. No necesitas ejecutarlo si ya cargaste las bases manualmente.
# Carga Base Cuidador Principal (STATA)
temp_cp <- tempfile()
download.file("https://observatorio.ministeriodesarrollosocial.gob.cl/storage/docs/elpi/2017/Base_Cuidador_Principal_ELPI_III(STATA)_241010.dta.zip", temp_cp)
elpicp <- haven::read_dta(unz(temp_cp, "Base_Cuidador_Principal_ELPI_III(STATA)_241010.dta"))
unlink(temp_cp); remove(temp_cp)
# Carga Base Niños y Niñas (SPSS)
temp_nna <- tempfile()
download.file("https://observatorio.ministeriodesarrollosocial.gob.cl/storage/docs/elpi/2017/Base_Ni%C3%B1os_y_Ni%C3%B1as_ELPI_III_(SPSS).sav.zip", temp_nna)
elpinna <- haven::read_sav(unz(temp_nna, "Base Niños y Niñas ELPI III (SPSS).sav"))
unlink(temp_nna); remove(temp_nna)
3. Limpieza y Preparación de las Bases (Por Separado)
Antes de unir las tablas, debemos prepararlas para asegurarnos de que contengan solo la información que necesitamos.
3.1 Base del Cuidador Principal (elpicp)
Esta base contiene información de todos los miembros del hogar, pero nos interesan las características asociadas al niño/a ELPI. Además, solo queremos a los niños/as de 10 años o más, ya que son quienes, por los lineamientos de aplicación de la escala de bienestar, contestaron dicho módulo.
elpicp_limpia <- elpicp %>%
# 1. Filtramos para quedarnos solo con las filas que corresponden al niño/a (tipopersona == 1)
filter(tipopersona == 1) %>%
# 2. Filtramos para quedarnos solo con los nna de 10 años o más (variable h3 es la edad)
filter(h3 >= 10) %>%
# 3. Seleccionamos las variables que nos interesan para nuestro análisis
select(folio, idregion, qaut_casen)
# Verificamos las dimensiones de nuestra base limpia
dim(elpicp_limpia)
## [1] 6066 3
Interpretación: Nuestra base de datos del cuidador principal (elpicp_limpia) ahora solo tiene 6,066 filas, que corresponden a los niños/as de 10 años o más, y 3 columnas con la información que necesitamos.
3.2 Base de Niños y Niñas (elpinna)
Esta base contiene las respuestas de bienestar. La limpiaremos y renombraremos las variables para que sea más fácil de usar.
elpinna_limpia <- elpinna %>%
# Nos quedamos solo con los niños/as de 10 años o más para ser consistentes
filter(edad >= 10) %>%
# Seleccionamos el identificador del hogar y las 6 preguntas de satisfacción, renombrándolas
select(folio,
satisf_familia = e1,
satisf_amigos = e2,
satisf_colegio = e3,
satisf_contigo = e4,
satisf_barrio = e5,
satisf_vida = e6)
# Vemos un resumen para verificar la limpieza
summary(elpinna_limpia)
## folio satisf_familia satisf_amigos satisf_colegio
## Min. :100011 Min. :1.000 Min. :1.000 Min. :1.000
## 1st Qu.:164216 1st Qu.:6.000 1st Qu.:6.000 1st Qu.:6.000
## Median :231891 Median :7.000 Median :7.000 Median :7.000
## Mean :237839 Mean :6.487 Mean :6.282 Mean :6.167
## 3rd Qu.:314551 3rd Qu.:7.000 3rd Qu.:7.000 3rd Qu.:7.000
## Max. :399641 Max. :7.000 Max. :7.000 Max. :7.000
## NA's :6 NA's :6 NA's :6
## satisf_contigo satisf_barrio satisf_vida
## Min. :1.000 Min. :1.000 Min. :1.000
## 1st Qu.:6.000 1st Qu.:5.000 1st Qu.:6.000
## Median :7.000 Median :7.000 Median :7.000
## Mean :6.336 Mean :5.912 Mean :6.489
## 3rd Qu.:7.000 3rd Qu.:7.000 3rd Qu.:7.000
## Max. :7.000 Max. :7.000 Max. :7.000
## NA's :6 NA's :6 NA's :6
Interpretación: El resumen nos muestra que las variables de satisfacción ahora tienen muy pocos NA's (solo 6). Esto confirma que nuestro filtro por edad fue correcto y que casi todos los niños y niñas de 10 años o más respondieron estas preguntas.
4. Combinando las Bases con left_join() (Paso Central)
Ahora que tenemos nuestras dos tablas limpias, las uniremos. La variable llave que conecta ambas tablas es folio, el identificador del hogar.
# Unimos las dos bases de datos.
# La tabla del cuidador es la "izquierda" (la principal), y le "pegamos" las respuestas de los niños/as.
elpi_completa <- left_join(elpicp_limpia, elpinna_limpia, by = "folio")
# Verificamos el resultado
head(elpi_completa)
## # A tibble: 6 × 9
## folio idregion qaut_casen satisf_familia satisf_amigos satisf_colegio
## <dbl> <dbl+lbl> <dbl+lbl> <dbl+lbl> <dbl+lbl> <dbl+lbl>
## 1 100011 15 [Regi\xf3n d… 2 [II] 5 [5] 4 [4] 4 [4]
## 2 100081 15 [Regi\xf3n d… 1 [I] 7 [7. Muy sat… 7 [7. Muy sa… 7 [7. Muy sat…
## 3 100091 15 [Regi\xf3n d… 1 [I] 7 [7. Muy sat… 7 [7. Muy sa… 7 [7. Muy sat…
## 4 100121 15 [Regi\xf3n d… 3 [III] 7 [7. Muy sat… 4 [4] 7 [7. Muy sat…
## 5 100131 15 [Regi\xf3n d… 4 [IV] 6 [6] 5 [5] 4 [4]
## 6 100151 15 [Regi\xf3n d… 1 [I] 5 [5] 7 [7. Muy sa… 4 [4]
## # ℹ 3 more variables: satisf_contigo <dbl+lbl>, satisf_barrio <dbl+lbl>,
## # satisf_vida <dbl+lbl>
dim(elpi_completa)
## [1] 6066 9
Interpretación: ¡Éxito! Ahora tenemos una única base de datos (elpi_completa) con 6,066 filas y 9 columnas, que contiene, para cada niño/a de 10 años o más, tanto sus características socioeconómicas (región, quintil) como sus respuestas de bienestar.
5. Construcción de Nuevas Variables
Con nuestra base unificada, podemos crear las variables que necesitamos para nuestro análisis.
5.1 Construcción de un Índice de Bienestar Subjetivo
Objetivo: Crear un puntaje global de satisfacción con la vida promediando las 6 preguntas.
elpi_completa <- elpi_completa %>%
mutate(
# Sumamos las 6 variables y dividimos por 6 para obtener el promedio
indice_bienestar = (satisf_familia + satisf_amigos + satisf_colegio + satisf_contigo + satisf_barrio + satisf_vida) / 6
)
# Exploremos la distribución de nuestro nuevo índice
summary(elpi_completa$indice_bienestar)
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 1.000 6.000 6.500 6.279 6.833 7.000 478
hist(elpi_completa$indice_bienestar, main = "Distribución del Índice de Bienestar", xlab = "Puntaje Promedio (1-7)")
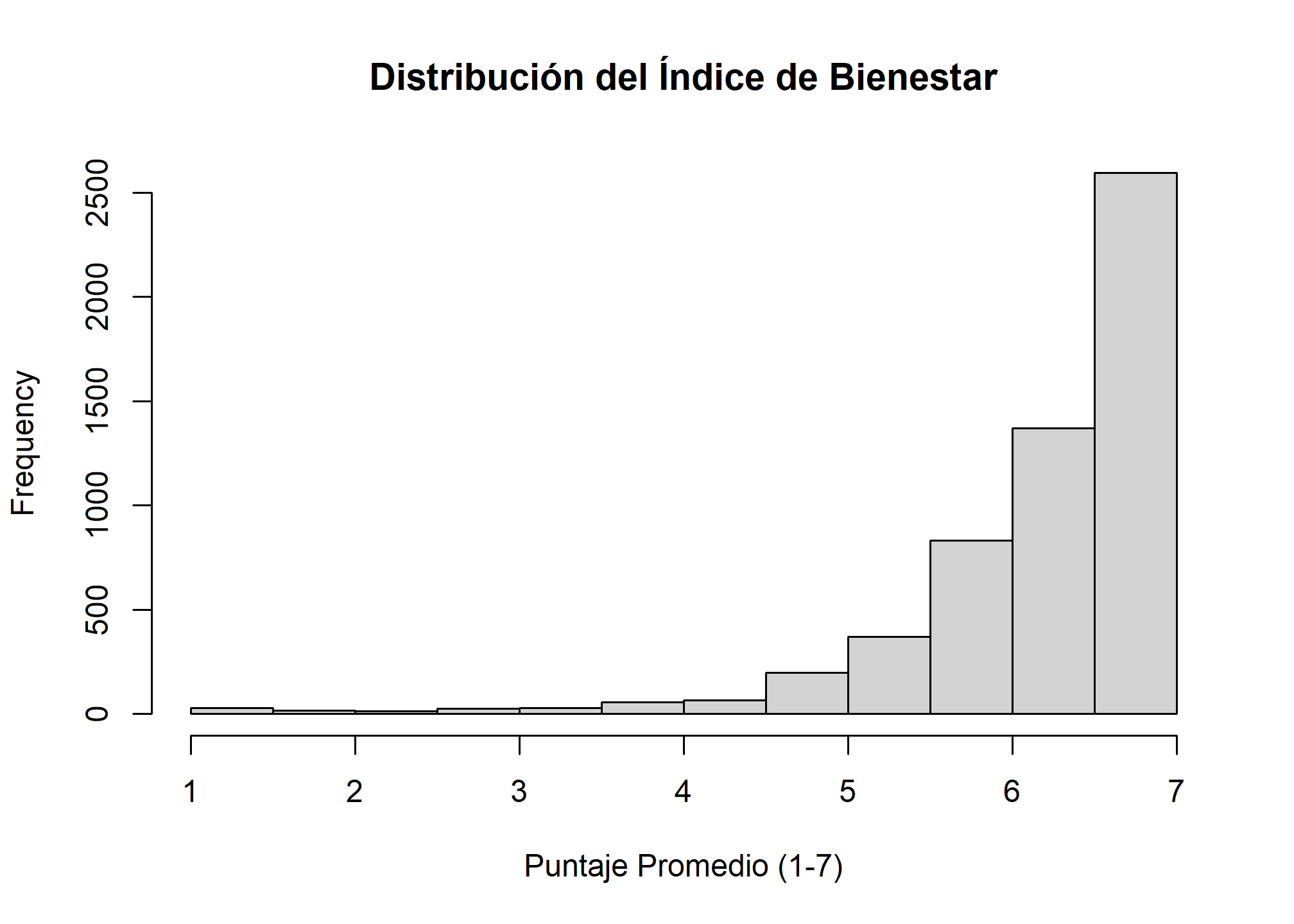
Interpretación: El summary nos muestra que el promedio del índice de bienestar es 6.28, con la mayoría de los casos concentrados en los valores altos de la escala (la mediana es 6.5). El histograma confirma esta distribución, fuertemente sesgada hacia la izquierda, lo que indica altos niveles generales de satisfacción en esta submuestra.
5.2 Construcción de una Tipología Socio-Territorial
Objetivo: Crear perfiles de estudiantes según si viven en la Región Metropolitana (código 13) y si pertenecen a los quintiles de mayores ingresos (4 y 5).
elpi_final <- elpi_completa %>%
mutate(
tipo_perfil = case_when(
idregion == 13 & qaut_casen %in% c(4, 5) ~ "RM - Quintil Alto",
idregion == 13 & !qaut_casen %in% c(4, 5) ~ "RM - Quintil Bajo/Medio",
idregion != 13 & qaut_casen %in% c(4, 5) ~ "Otras Regiones - Quintil Alto",
idregion != 13 & !qaut_casen %in% c(4, 5) ~ "Otras Regiones - Quintil Bajo/Medio",
TRUE ~ "Sin Información" # Para casos con NA
)
)
# Verificamos el tamaño de cada grupo con table()
table(elpi_final$tipo_perfil)
##
## Otras Regiones - Quintil Alto Otras Regiones - Quintil Bajo/Medio
## 728 3385
## RM - Quintil Alto RM - Quintil Bajo/Medio
## 396 1557
6. Análisis Descriptivo Final
Pregunta de Investigación: ¿Existen diferencias en el bienestar subjetivo (nuestro índice) según el perfil socio-territorial de los niños y niñas?
elpi_final %>%
# Agrupamos por nuestra nueva tipología
group_by(tipo_perfil) %>%
# Calculamos el promedio del índice y el número de casos por grupo
summarise(
bienestar_promedio = mean(indice_bienestar, na.rm = TRUE),
n_casos = n()
) %>%
# Ordenamos para ver los resultados más claramente
arrange(desc(bienestar_promedio))
## # A tibble: 4 × 3
## tipo_perfil bienestar_promedio n_casos
## <chr> <dbl> <int>
## 1 Otras Regiones - Quintil Alto 6.37 728
## 2 Otras Regiones - Quintil Bajo/Medio 6.31 3385
## 3 RM - Quintil Alto 6.25 396
## 4 RM - Quintil Bajo/Medio 6.16 1557
Actividad de Interpretación: Observa la tabla de resultados. ¿Qué grupo presenta el mayor promedio de bienestar? ¿Y el menor? Vemos que los niños/as de regiones de quintiles altos reportan el mayor bienestar, mientras que los de la RM de quintiles bajos/medios, el menor. ¿Te sorprenden estos resultados? ¿Qué hipótesis sociológica podrías formular a partir de esta tabla?
7. Actividad de Desafío
Ahora te toca a ti.
Pregunta: ¿Cómo varía la satisfacción específica con la vida familiar (satisf_familia) y con el colegio (satisf_colegio) a través de los quintiles de ingreso (qaut_casen)?
Instrucciones:
- Usa la base
elpi_final. - Agrupa por la variable
qaut_casen. - Calcula el promedio de
satisf_familiaysatisf_colegiopara cada quintil. - No olvides manejar los
NAy contar el número de casos por grupo.
# Escribe tu código aquí